library(tidyverse)TP6 Apprentissage par processus Gaussiens Multi-tâches
Contexte
Pour ce TP, nous allons principalement utiliser le package MagmaClustR qui permet de manipuler des processus gaussiens multi-tâches. Nous allons nous appliquer ces méthodes sur des données simulées.
Installation du package MagmaClust.
# install.packages("MagmaClustR")Jeu de données simulées
Pour commencer, nous allons simuler des données multi-tâches. Nous allons considérer 10 tâches et 10 points d’entrée (x) pour chaque tâche. Le jeu de données est simulé à l’aide du code suivant :
library(tidyverse)
library(MagmaClustR)
set.seed(42)
data = simu_db(M = 10, N = 10, common_input = FALSE)
data# A tibble: 100 × 3
ID Input Output
<chr> <dbl> <dbl>
1 1 1.6 42.7
2 1 1.75 43.1
3 1 2.2 47.2
4 1 4.55 57.7
5 1 4.6 57.3
6 1 4.75 55.8
7 1 5.05 53.2
8 1 6.1 51.7
9 1 7.45 66.0
10 1 8.55 79.4
# ℹ 90 more rowsVisualisez l’ensemble des données simulées. Chaque tâche doit être représentée par une couleur différente. Que remarquez-vous sur les différentes tâches ?
A partir du jeu de données initial, définissez un jeu de données d’entrainement avec 9 tâches, et conserver toutes les observations pour ces tâches. Pour la tâche restante, qui sera celle de test, séparez à nouveau les données, afin de ne conserver que la moitié des observations pour la prédiction, et le reste pour le test.
Visualiser les données de la tâche de test en colorant différemment les points servant à la prédiction et les points de test.
- Vous pouvez utiliser le package
ggplot2pour visualiser les données ‘à la main’, ou utiliser directement la fonctionMagmaClustR:::plot_db(). - Vous pouvez utiliser la fonction
dplyr::filter()pour sélectionner les tâches et observations souhaitées. - Vous pouvez utiliser la fonction
dplyr::mutate()pour créer une nouvelle colonne indiquant si une observation est utilisée pour la prédiction ou pour le test. Ensuite, l’argumentcolordeggplot2::geom_point()peut être utilisé pour colorer les points en fonction de cette nouvelle colonne.
#| warning: false
#| message: false
## Simple visualisation with build-in function
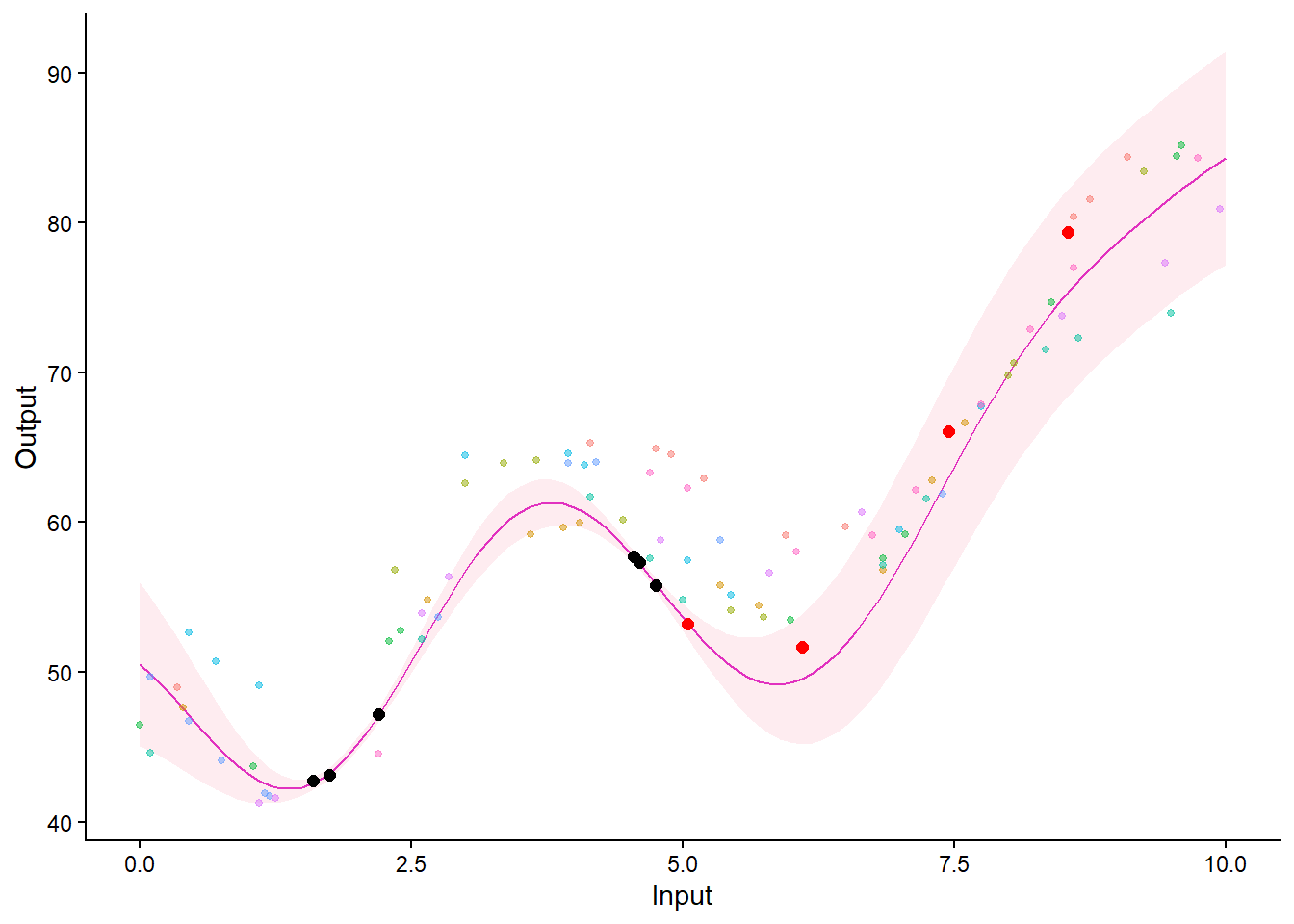
MagmaClustR:::plot_db(data)`geom_smooth()` using method = 'loess' and formula = 'y ~ x'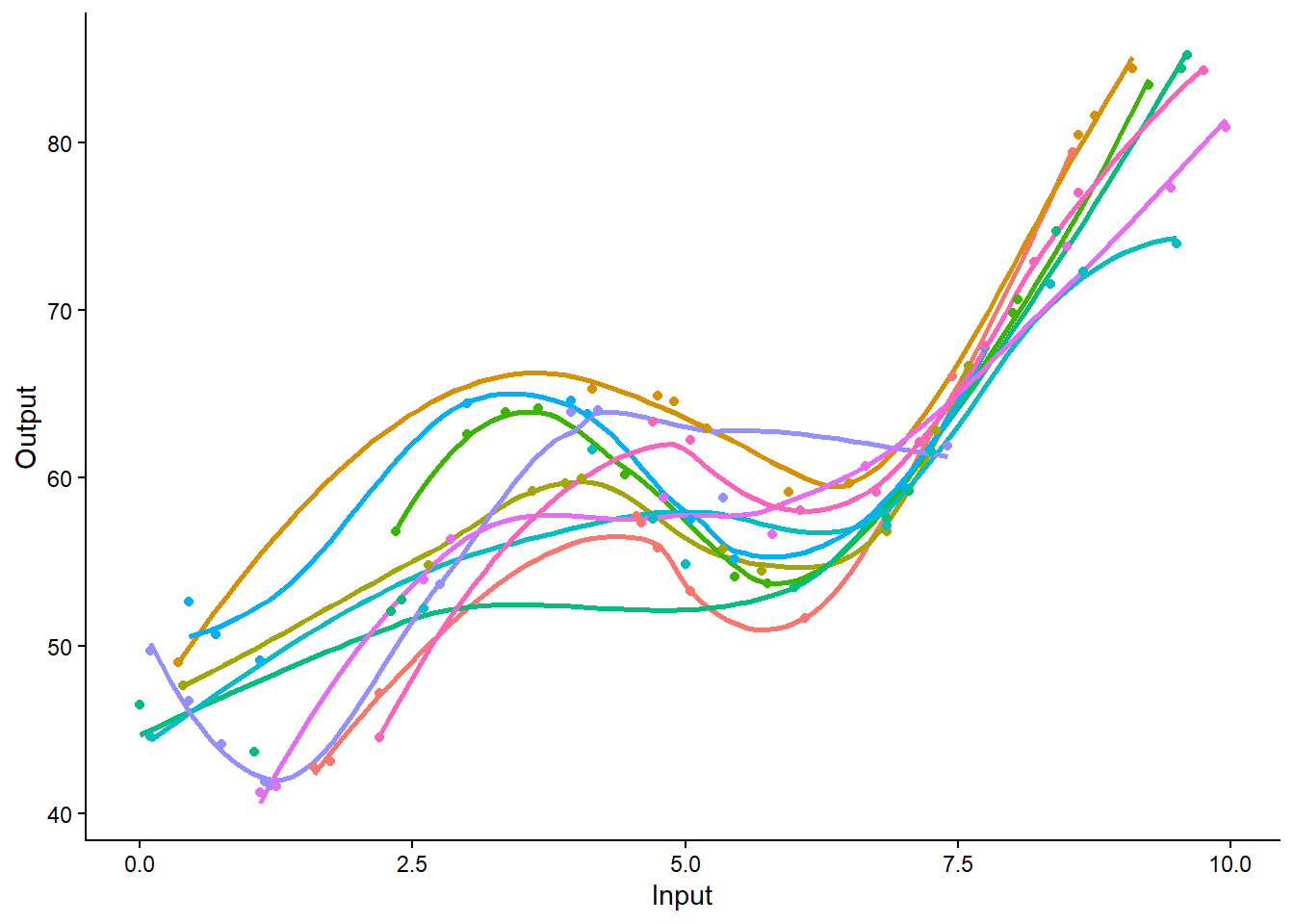
## More custom version with ggplot2
ggplot(data) +
geom_point(aes(x = Input, y = Output, color = ID)) +
theme_classic()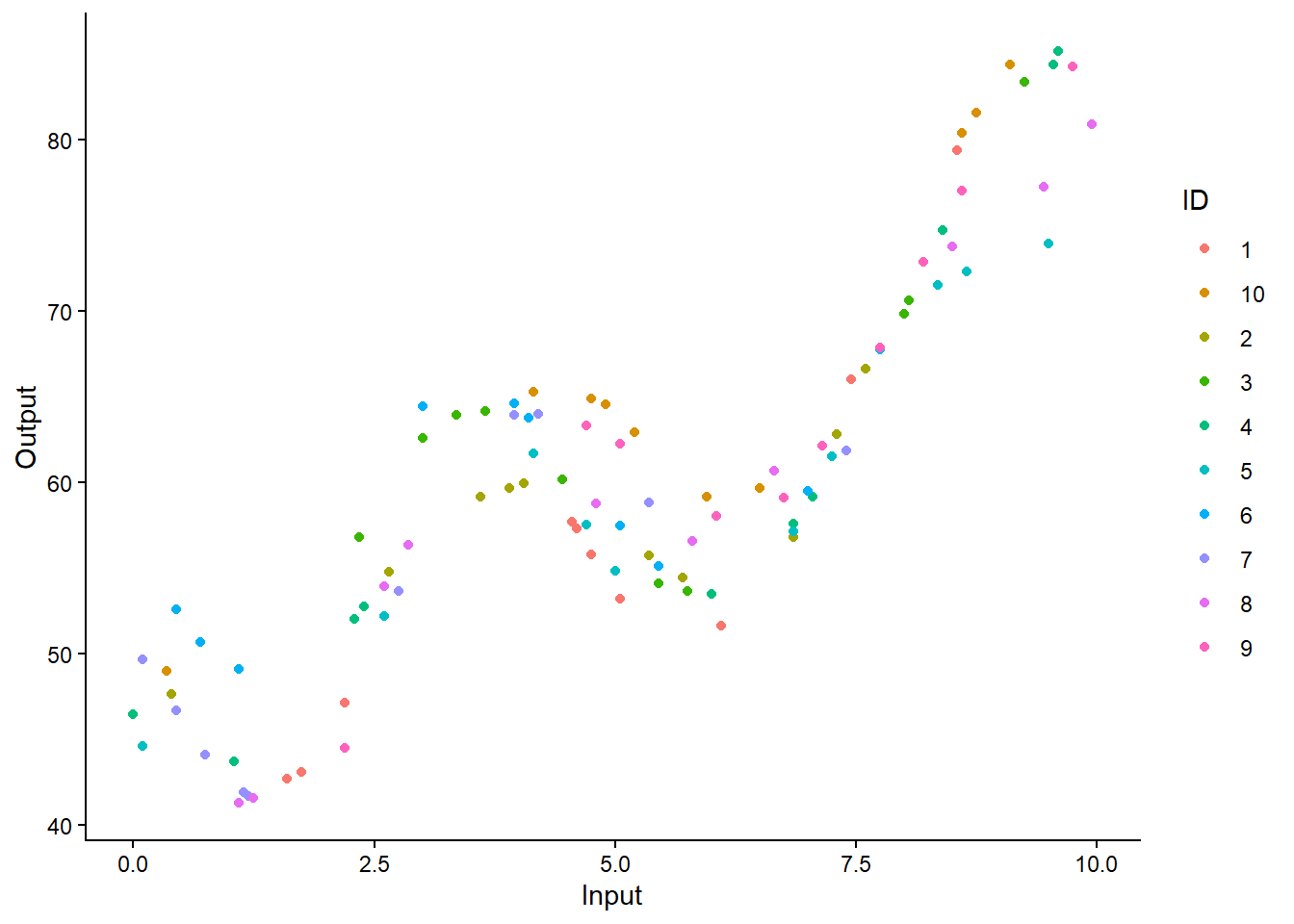
## Splitting the data into training and test sets
train_data = data %>% filter(ID != 1)
test_data = data %>%
filter(ID == 1) %>%
mutate("Set" = ifelse(Input <= 5, "Train", "Test"))
# Visualizing the test task with different colors for train and test points
ggplot(test_data) +
geom_point(aes(x = Input, y = Output, color = Set)) +
theme_classic()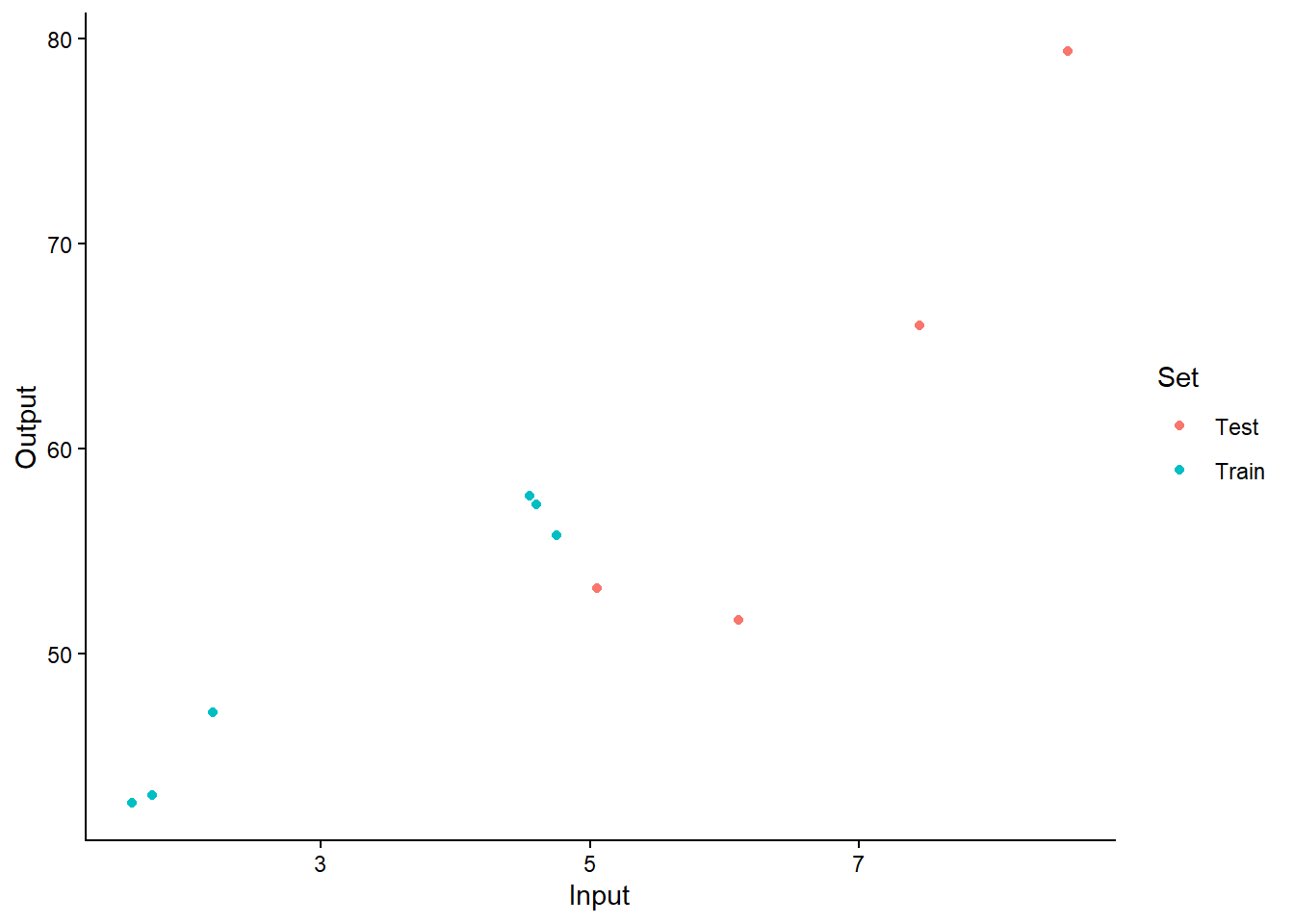
Modélisation avec un Processus Gaussien Multi-tâches
Nous allons maintenant modéliser les données simulées à l’aide d’un processus gaussien multi-tâches. Nous allons utiliser les données d’entrainement définies précédemment pour ajuster le modèle, puis nous allons effectuer des prédictions sur les points de test de la tâche restante.
En utilisant la fonction
train_magma(), ajustez un modèle de processus gaussien multi-tâches sur les données d’entrainement. Quels sont les hyperparamètres appris par le modèle ?Visualiser le processus moyen issu du modèle ajusté sur les données d’entrainement.
Utilisez la fonction
pred_magma()pour effectuer des prédictions sur les points de test de la tâche restante.Personnalisez la visualisation des prédictions en utilisant les différents arguments de la fonction
plot_magma(). Comparez la prédiction multi-tâches avec la prédiction mono-tâche obtenue précédemment.
La fonction
train_magma()retourne un objet contenant les hyperparamètres appris. Vous pouvez accéder à ces hyperparamètres en utilisant$hp_isur l’objet retourné.La fonction
plot_gp()permet de visualiser le processus moyen appris pendant l’entrainement. Il peut être trouvé dans le modèle entrainé avec l’argument$hyperpost$pred.La fonction
pred_magma()prend en entrée le modèle entrainé et les données de test, et retourne les prédictions.La fonction
plot_magma()permet de visualiser les prédictions. Vous pouvez utiliser les argumentsdata,data_train, ou autre, pour personnaliser les différentes composantes de la visualisation.
# 1. Training the multi-task GP model
model_magma = train_magma(data = train_data)The 'prior_mean' argument has not been specified. The hyper_prior mean function is thus set to be 0 everywhere.
The 'ini_hp_0' argument has not been specified. Random values of hyper-parameters for the mean process are used as initialisation.
The 'ini_hp_i' argument has not been specified. Random values of hyper-parameters for the individal processes are used as initialisation.
EM algorithm, step 1: 2.62 seconds
Value of the likelihood: -390.82011 --- Convergence ratio = Inf
EM algorithm, step 2: 1.67 seconds
Value of the likelihood: -347.23844 --- Convergence ratio = 0.12551
EM algorithm, step 3: 1.4 seconds
Value of the likelihood: -336.95598 --- Convergence ratio = 0.03052
EM algorithm, step 4: 1.32 seconds
Value of the likelihood: -321.57544 --- Convergence ratio = 0.04783
EM algorithm, step 5: 1.53 seconds
Value of the likelihood: -307.54404 --- Convergence ratio = 0.04562
EM algorithm, step 6: 1.34 seconds
Value of the likelihood: -302.44967 --- Convergence ratio = 0.01684
EM algorithm, step 7: 0.82 seconds
Value of the likelihood: -300.53246 --- Convergence ratio = 0.00638
EM algorithm, step 8: 0.91 seconds
Value of the likelihood: -298.89146 --- Convergence ratio = 0.00549
EM algorithm, step 9: 0.9 seconds
Value of the likelihood: -297.39381 --- Convergence ratio = 0.00504
EM algorithm, step 10: 1.31 seconds
Value of the likelihood: -295.86073 --- Convergence ratio = 0.00518
EM algorithm, step 11: 0.84 seconds
Value of the likelihood: -294.50046 --- Convergence ratio = 0.00462
EM algorithm, step 12: 1.36 seconds
Value of the likelihood: -293.13738 --- Convergence ratio = 0.00465
EM algorithm, step 13: 1.71 seconds
Value of the likelihood: -291.91738 --- Convergence ratio = 0.00418
EM algorithm, step 14: 1.21 seconds
Value of the likelihood: -290.68546 --- Convergence ratio = 0.00424
EM algorithm, step 15: 0.95 seconds
Value of the likelihood: -289.55733 --- Convergence ratio = 0.0039
EM algorithm, step 16: 0.8 seconds
Value of the likelihood: -288.50382 --- Convergence ratio = 0.00365
EM algorithm, step 17: 1.02 seconds
Value of the likelihood: -287.47833 --- Convergence ratio = 0.00357
EM algorithm, step 18: 1.23 seconds
Value of the likelihood: -286.45615 --- Convergence ratio = 0.00357
EM algorithm, step 19: 1.06 seconds
Value of the likelihood: -285.60156 --- Convergence ratio = 0.00299
EM algorithm, step 20: 0.75 seconds
Value of the likelihood: -284.54659 --- Convergence ratio = 0.00371
EM algorithm, step 21: 1.16 seconds
Value of the likelihood: -284.1524 --- Convergence ratio = 0.00139
EM algorithm, step 22: 0.97 seconds
Value of the likelihood: -283.89756 --- Convergence ratio = 9e-04
The EM algorithm successfully converged, training is completed.
model_magma$hp_i # Display learned hyperparameters# A tibble: 9 × 4
ID se_variance se_lengthscale noise
<chr> <dbl> <dbl> <dbl>
1 10 2.40 0.512 -3.58
2 2 2.40 0.512 -3.58
3 3 2.40 0.512 -3.58
4 4 2.40 0.512 -3.58
5 5 2.40 0.512 -3.58
6 6 2.40 0.512 -3.58
7 7 2.40 0.512 -3.58
8 8 2.40 0.512 -3.58
9 9 2.40 0.512 -3.58# 2. Visualizing the learned mean process
plot_gp(model_magma$hyperpost$pred)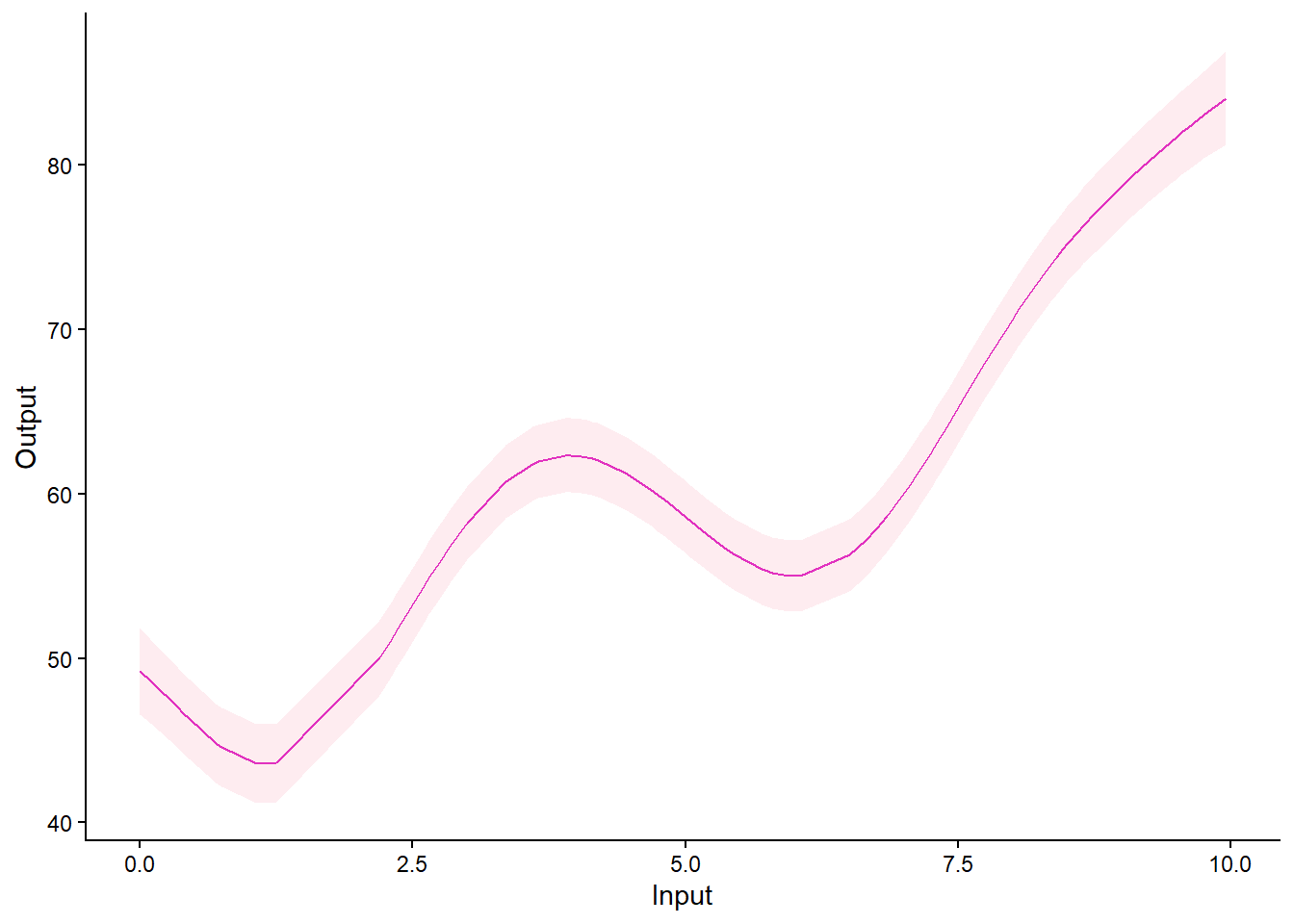
# 3. Making predictions on the test data
pred_data = test_data %>% filter(Set == "Train") %>% select(-Set)
predictions = pred_magma(data = pred_data, trained_model = model_magma, grid_inputs = seq(0, 10, 0.1))The hyper-posterior distribution of the mean process provided in 'hyperpost' argument isn't evaluated on the expected inputs.
Start evaluating the hyper-posterior on the correct inputs...
The 'prior_mean' argument has not been specified. The hyper-prior mean function is thus set to be 0 everywhere.
Done!
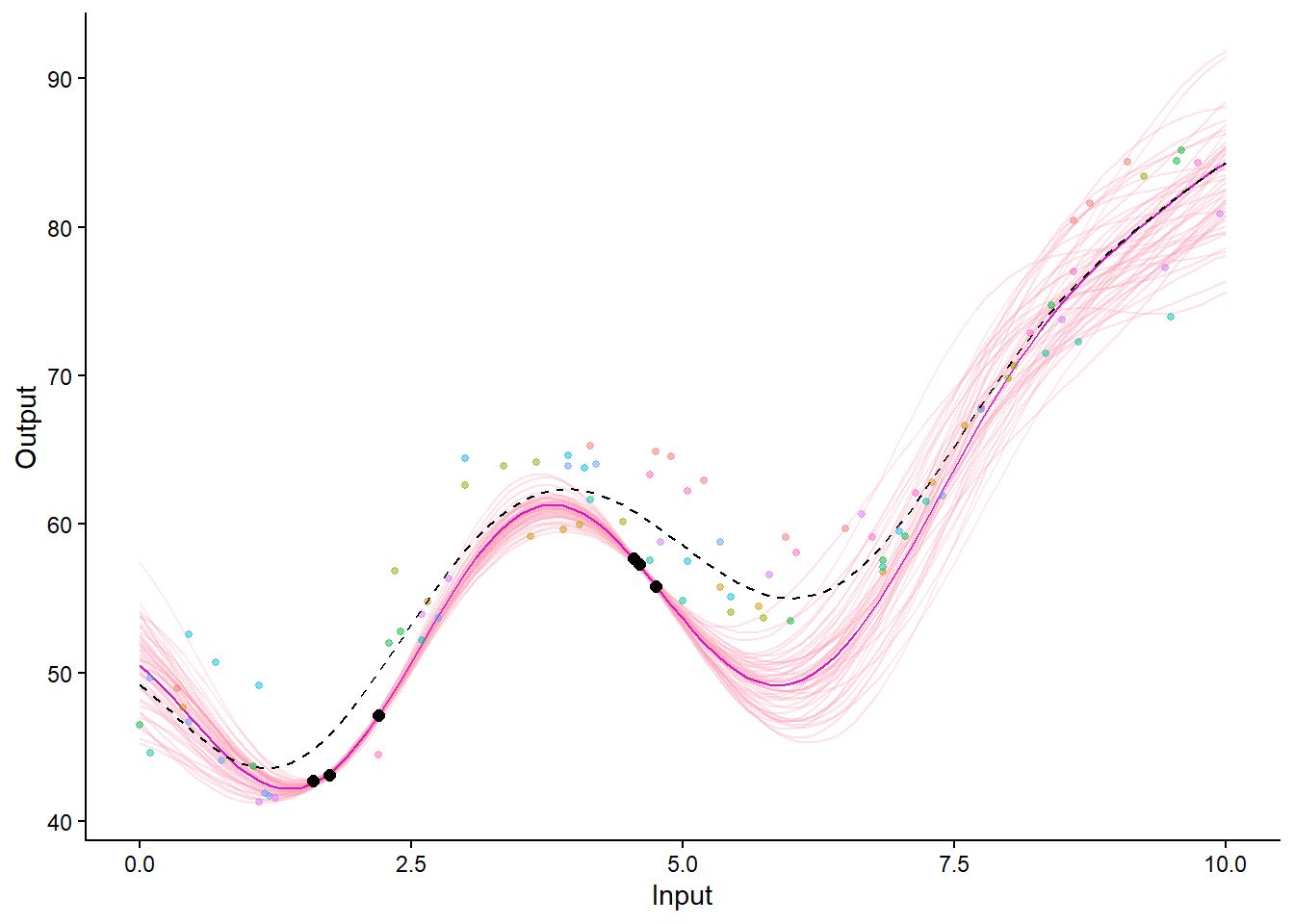
# 4. Visualizing the predictions
plot_magma(predictions)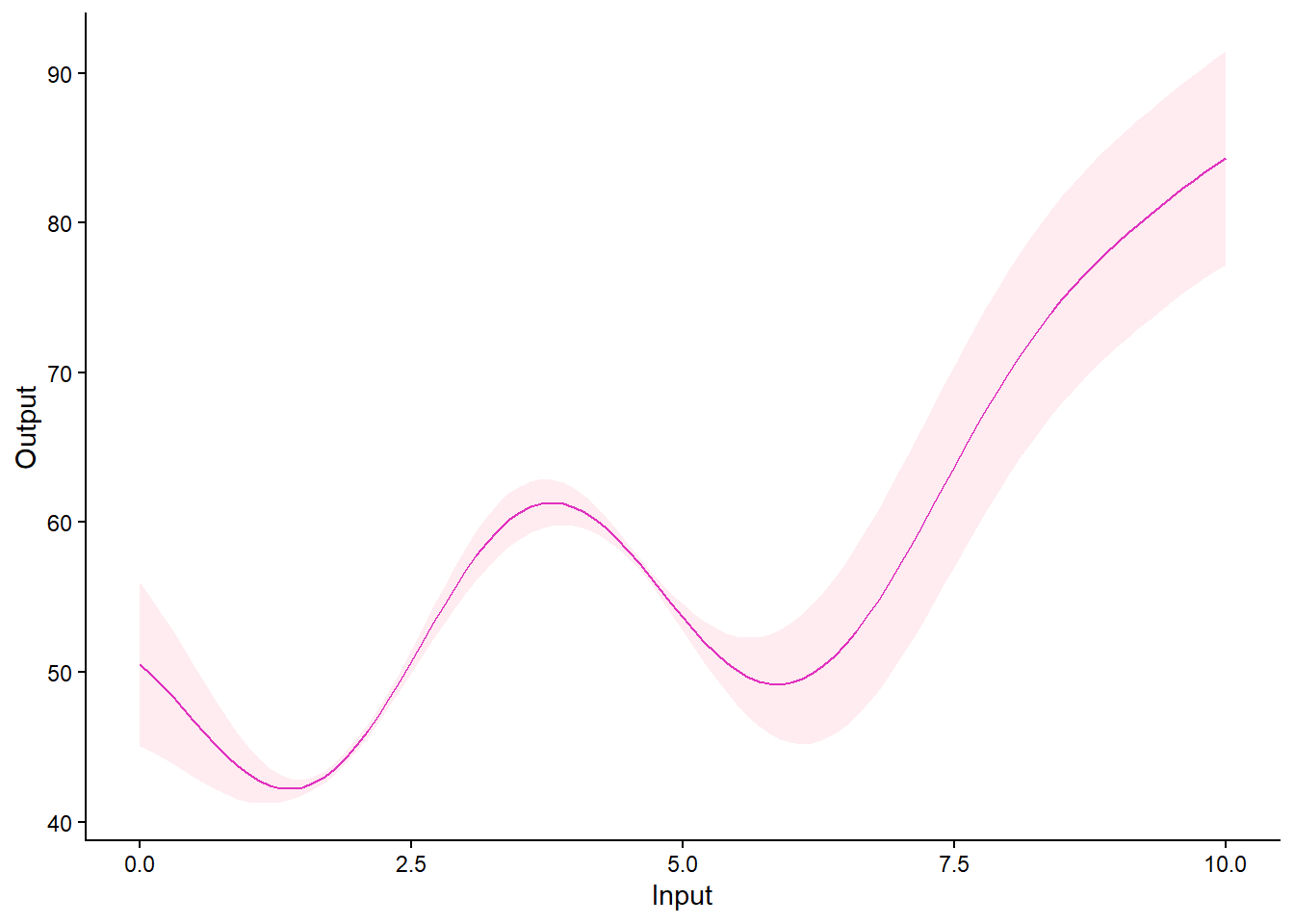
plot_magma(predictions, data = pred_data)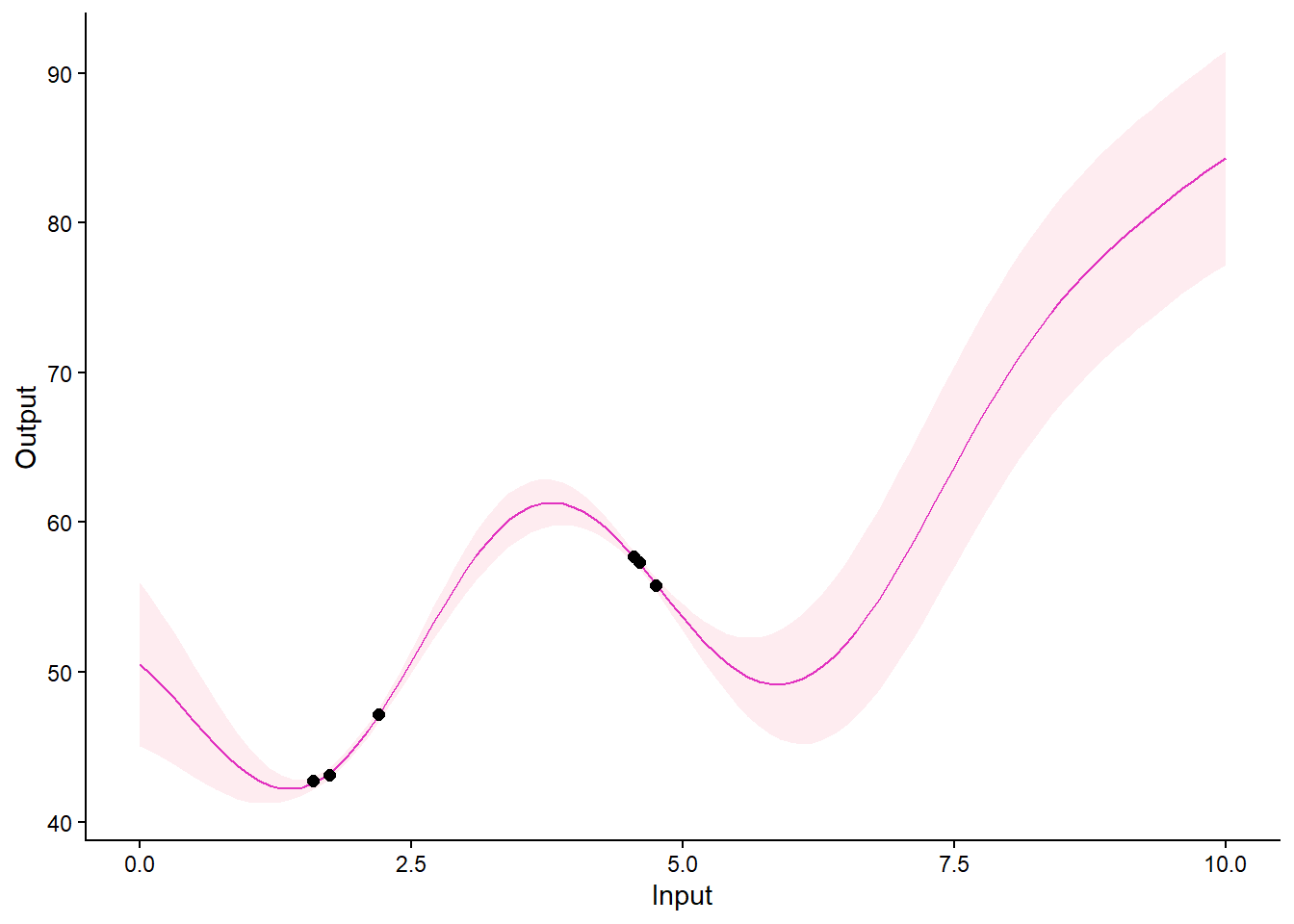
plot_magma(predictions, data = test_data, data_train = train_data)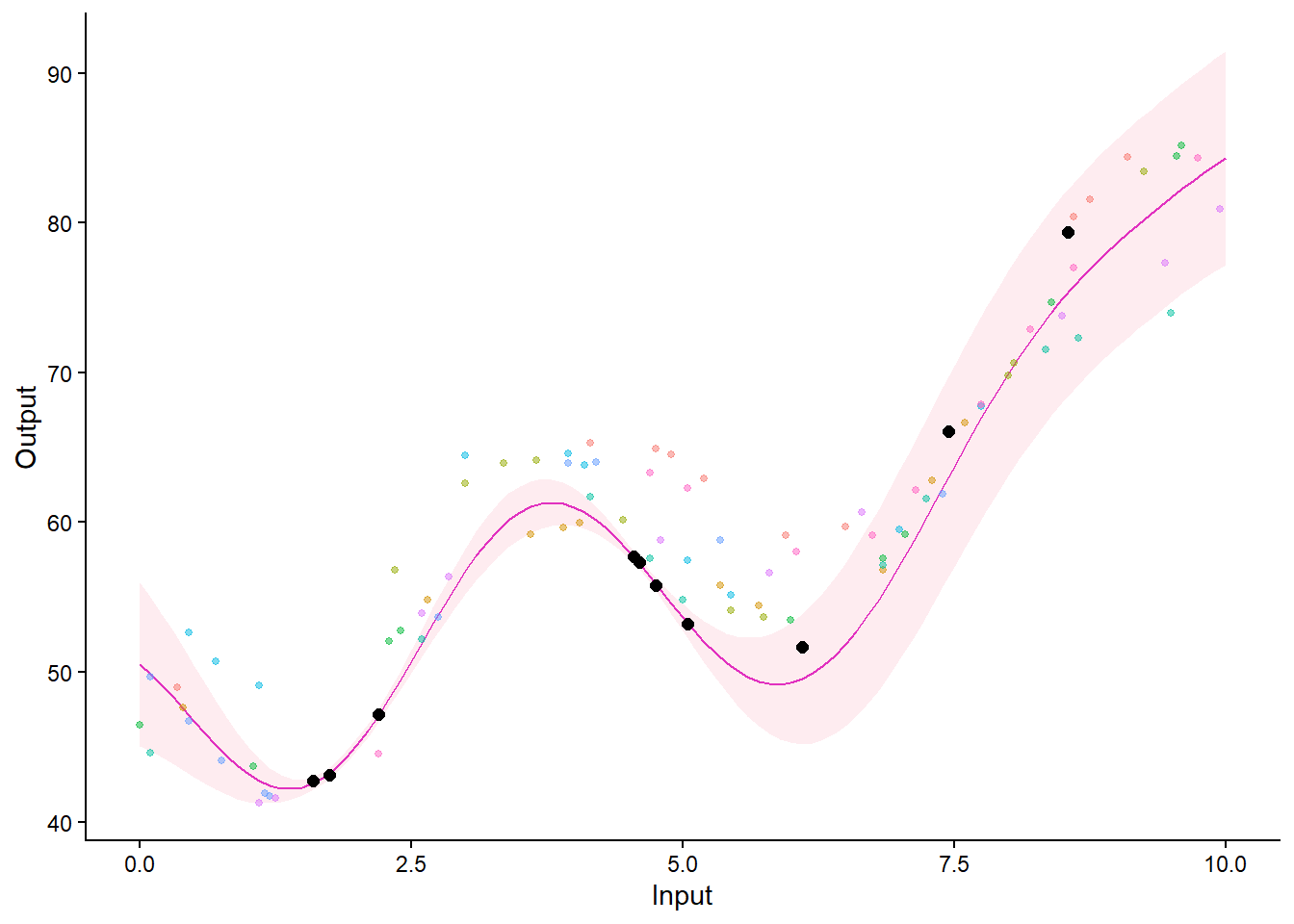
plot_magma(predictions, data = test_data, data_train = train_data) +
geom_point(data = test_data %>% filter(Set == "Test"),
aes(x = Input, y = Output), color = "red", size = 2)