library(tidyverse)TP8 : Clustering et mélange de processus Gaussiens Multi-tâches
Contexte
Pour ce TP, nous allons principalement utiliser le package MagmaClustR qui permet de manipuler des processus gaussiens multi-tâches. Nous allons nous appliquer ces méthodes sur des données simulées en 1 dimension, puis en 2 dimensions, et enfin sur des données réelles. N’hésitez pas à consulter la page web de documentation du package pour plus de détails : https://arthurleroy.github.io/MagmaClustR/.
# install.packages("MagmaClustR")Jeu de données simulées
Pour commencer, nous allons simuler des données multi-tâches. Nous allons considérer 3 clusters contenant chacun 5 tâches, chacune observée en 10 points irréguliers. Le jeu de données est simulé à l’aide du code suivant :
library(tidyverse)
library(MagmaClustR)
set.seed(424)
data = simu_db(M = 5, N = 10, K = 3, common_input = FALSE)
data# A tibble: 150 × 3
ID Input Output
<chr> <dbl> <dbl>
1 ID1-Clust1 0.25 33.3
2 ID1-Clust1 0.4 33.6
3 ID1-Clust1 2.4 54.4
4 ID1-Clust1 5.45 41.9
5 ID1-Clust1 6.25 41.7
6 ID1-Clust1 6.7 42.7
7 ID1-Clust1 7.45 39.8
8 ID1-Clust1 8.2 35.6
9 ID1-Clust1 8.5 34.4
10 ID1-Clust1 9.15 35.2
# ℹ 140 more rowsVisualisez l’ensemble des données simulées. Chaque tâche doit être représentée par une couleur différente.
A partir du jeu de données initial, définissez un jeu de données d’entrainement avec 14 tâches, et conserver toutes les observations pour ces tâches. Pour la tâche restante, qui sera celle de test, séparez à nouveau les données, afin de ne conserver que la moitié des observations pour la prédiction, et le reste pour le test.
En utilisant la fonction
train_magmaclust(), ajustez un modèle de mélange de processus gaussiens multi-tâches en choisissant 3 clusters.Extraire du modèle entrainé les probabilités d’appartenir aux différents clusters pour chaque tâche.
Utilisez la fonction
pred_magmaclust()pour effectuer des prédictions sur les points de test de la tâche restante.Réutiliser la fonction
pred_magmaclust()avec les argumentsget_full_cov = TRUEetget_hyperpost = TRUE, afin de sauvegarder les covariances complètes et les processus moyens entrainés.Visualisez les prédictions à l’aide de la fonction
plot_magmaclust(), en affichant les prédictions sous forme d’échantillons, en ajoutant les données de prédiction, de test, d’entrainement, ainsi que les processus moyens, coloriés par cluster d’appartenance le plus probable. Vous pouvez personnaliser la visualisation en utilisant les argumentsdata,data_train, etc.
Vous pouvez utiliser le package
ggplot2pour visualiser les données ‘à la main’, ou utiliser directement la fonctionMagmaClustR:::plot_db().Vous pouvez utiliser la fonction
dplyr::filter()pour sélectionner les tâches et observations souhaitées.La fonction
train_magmaclust()retourne un objet contenant les probabilités d’appartenance. Le nombre de cluster est défini par l’argumentnb_cluster.Les probabilitiés d’appartenance peuvent être trouvées dans le modèle entrainé avec l’argument
$hyperpost$mixture.La fonction
pred_magmaclust()prend en entrée le modèle entrainé et les données de test, et retourne les prédictions.La fonction
data_allocate_cluster()appliquée au modèle entrainé permet d’allouer chaque tâche à son cluster le plus probable, ce qui est utile pour la visualisation. La visualisation sous forme d’échantillon est possible avec l’argumentsamples = TRUE. Les processus moyens peuvent être affichés avec l’argumentprior_meanqui peut prendre la valeur de l’argument$hyperpost$meandu modèle entrainé.
#| warning: false
#| message: false
## Simple visualisation with build-in function
MagmaClustR:::plot_db(data)`geom_smooth()` using method = 'loess' and formula = 'y ~ x'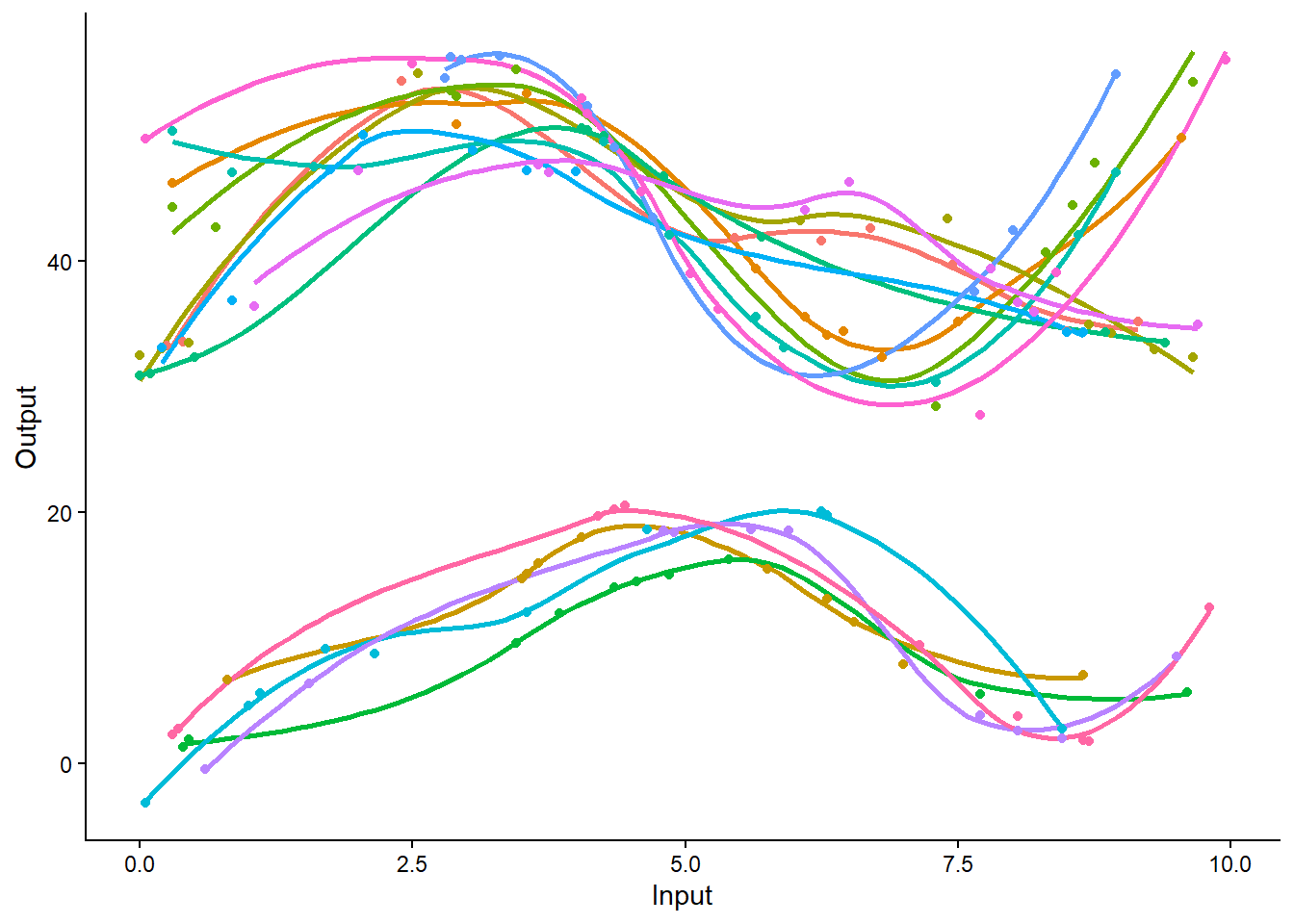
## More custom version with ggplot2
ggplot(data) +
geom_point(aes(x = Input, y = Output, color = ID)) +
theme_classic()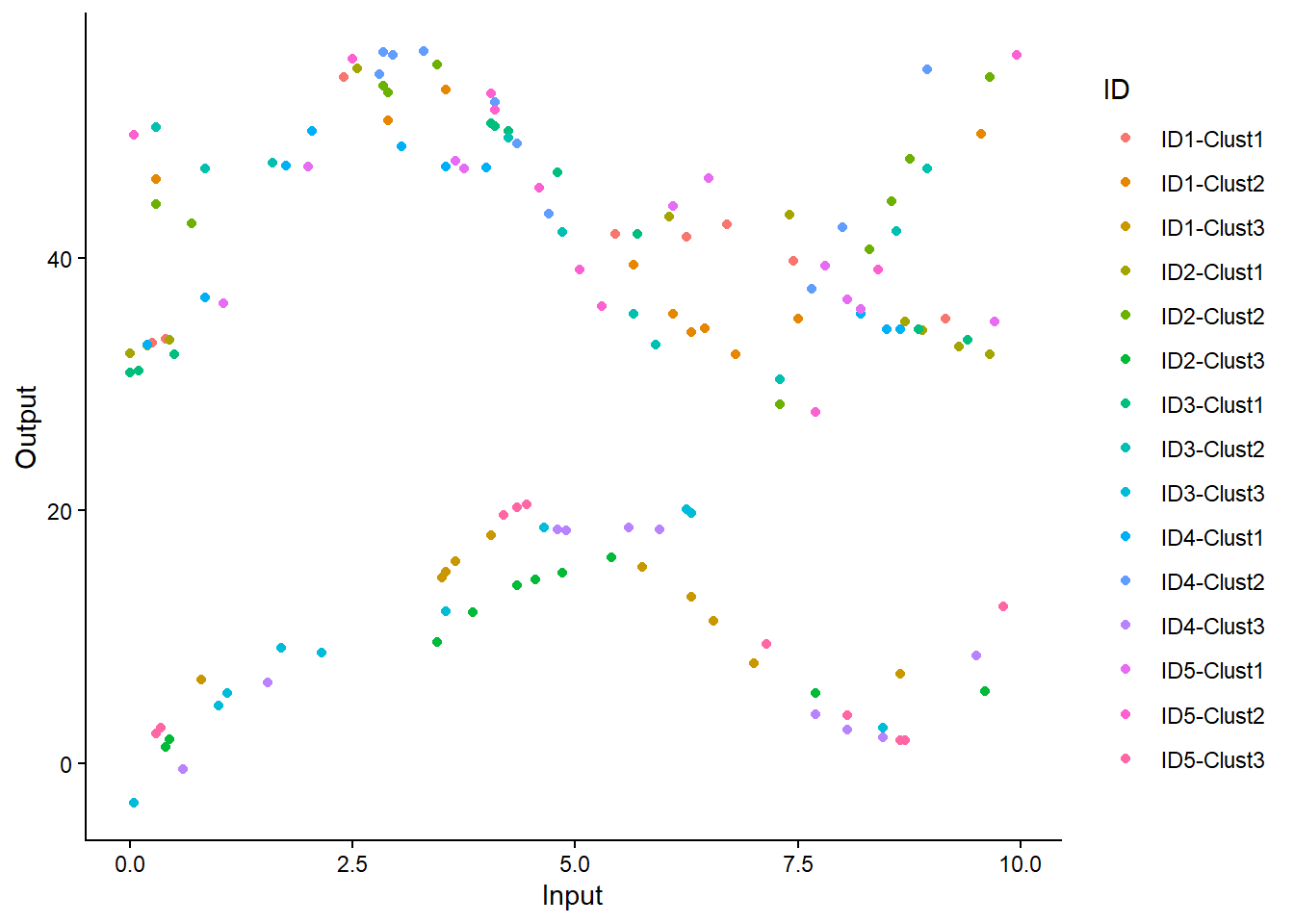
## Splitting the data into training and test sets
list_ID = unique(data$ID)
train_data = data %>% filter(ID != list_ID[1])
pred_data = data %>% filter(ID == list_ID[1], Input <= 5)
test_data = data %>% filter(ID == list_ID[1], Input > 5)
## Training the mixture of multi-task GP model
model_magmaclust = train_magmaclust(data = train_data, nb_cluster = 3)The 'ini_hp_i' argument has not been specified. Random values of hyper-parameters for the individual processes are used as initialisation.
The 'ini_hp_k' argument has not been specified. Random values of hyper-parameters for the mean processes are used as initialisation.
The 'prior_mean' argument has not been specified. The hyper_prior mean function is thus set to be 0 everywhere.
VEM algorithm, step 1: 4.32 seconds
Value of the elbo: -819.80335 --- Convergence ratio = Inf
VEM algorithm, step 2: 3.18 seconds
Value of the elbo: -791.67646 --- Convergence ratio = 0.03553
VEM algorithm, step 3: 3.93 seconds
Value of the elbo: -784.42229 --- Convergence ratio = 0.00925
VEM algorithm, step 4: 6.64 seconds
Value of the elbo: -779.18972 --- Convergence ratio = 0.00672
VEM algorithm, step 5: 3.19 seconds
Value of the elbo: -777.49955 --- Convergence ratio = 0.00217
VEM algorithm, step 6: 3.43 seconds
Value of the elbo: -776.5358 --- Convergence ratio = 0.00124
VEM algorithm, step 7: 2.76 seconds
Value of the elbo: -775.91091 --- Convergence ratio = 0.00081
The EM algorithm successfully converged, training is completed.
## Extracting mixture probabilities
model_magmaclust$hyperpost$mixture # Display mixture probabilities# A tibble: 14 × 4
ID K1 K2 K3
<chr> <dbl> <dbl> <dbl>
1 ID2-Clust1 0 0 1
2 ID3-Clust1 0 0 1
3 ID3-Clust3 0 1 0
4 ID5-Clust2 1 0 0
5 ID4-Clust1 0.00067 0 0.999
6 ID1-Clust2 1.000 0 0.00003
7 ID2-Clust2 1 0 0
8 ID3-Clust2 1 0 0
9 ID5-Clust3 0 1 0
10 ID2-Clust3 0 1 0
11 ID4-Clust3 0 1 0
12 ID1-Clust3 0 1 0
13 ID5-Clust1 0.00001 0 1.000
14 ID4-Clust2 1.000 0 0.00001## Making predictions on the test data
pred = pred_magmaclust(data = pred_data, trained_model = model_magmaclust, grid_inputs = seq(0, 10, 0.1))The hyper-posterior distribution of the mean process provided in 'hyperpost' argument isn't evaluated on the expected inputs. Start evaluating the hyper-posterior on the correct inputs...
The 'prior_mean_k' argument has not been specified. The hyper-prior mean functions are thus set to be 0 everywhere.
Done!
Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.
ℹ The deprecated feature was likely used in the MagmaClustR package.
Please report the issue at
<https://github.com/ArthurLeroy/MagmaClustR/issues>.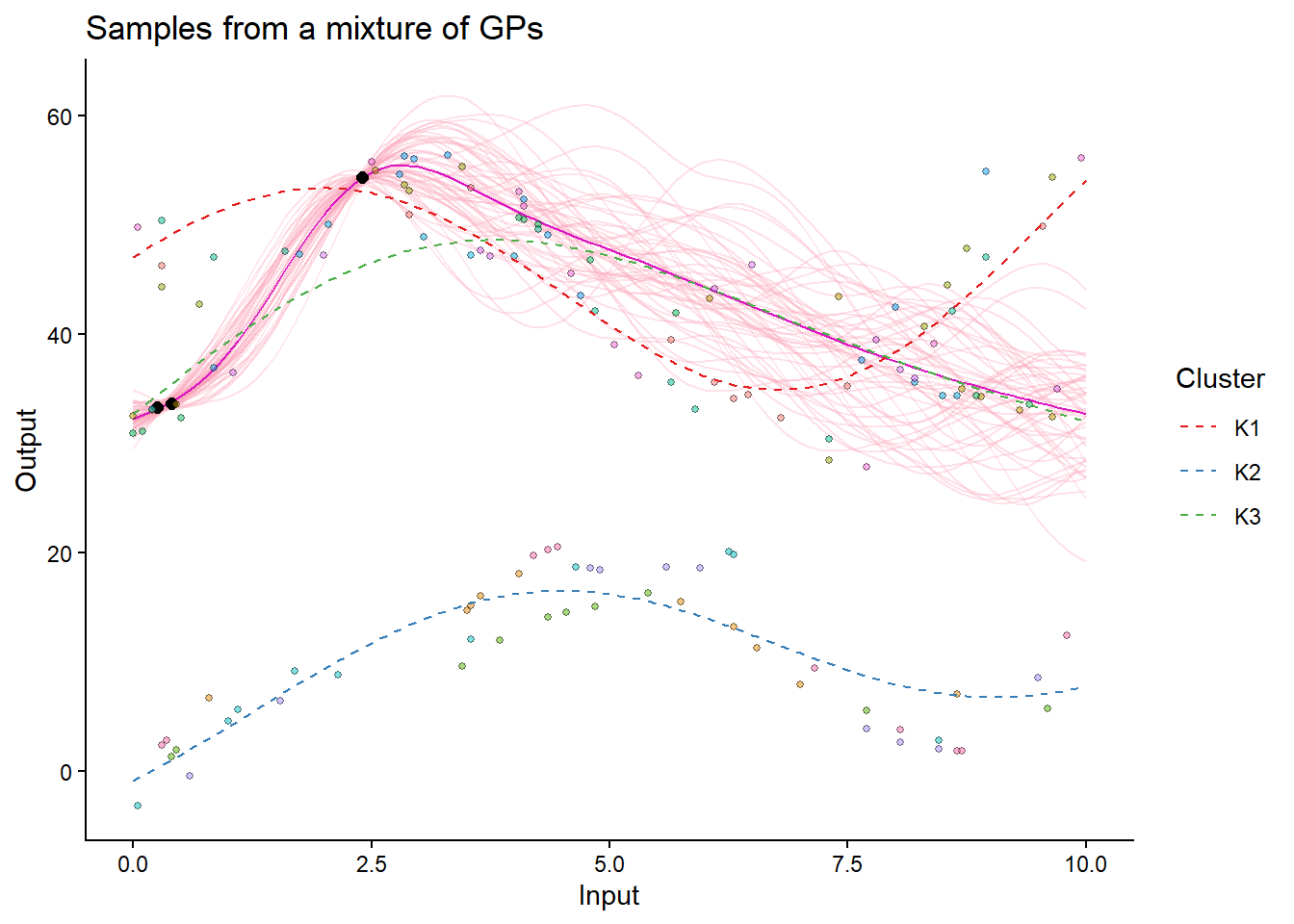
## Making predictions with full covariance and hyperposterior
pred_complete = pred_magmaclust(
data = pred_data,
trained_model = model_magmaclust,
grid_inputs = seq(0, 10, 0.1),
get_full_cov = TRUE,
get_hyperpost = TRUE)The hyper-posterior distribution of the mean process provided in 'hyperpost' argument isn't evaluated on the expected inputs. Start evaluating the hyper-posterior on the correct inputs...
The 'prior_mean_k' argument has not been specified. The hyper-prior mean functions are thus set to be 0 everywhere.
Done!
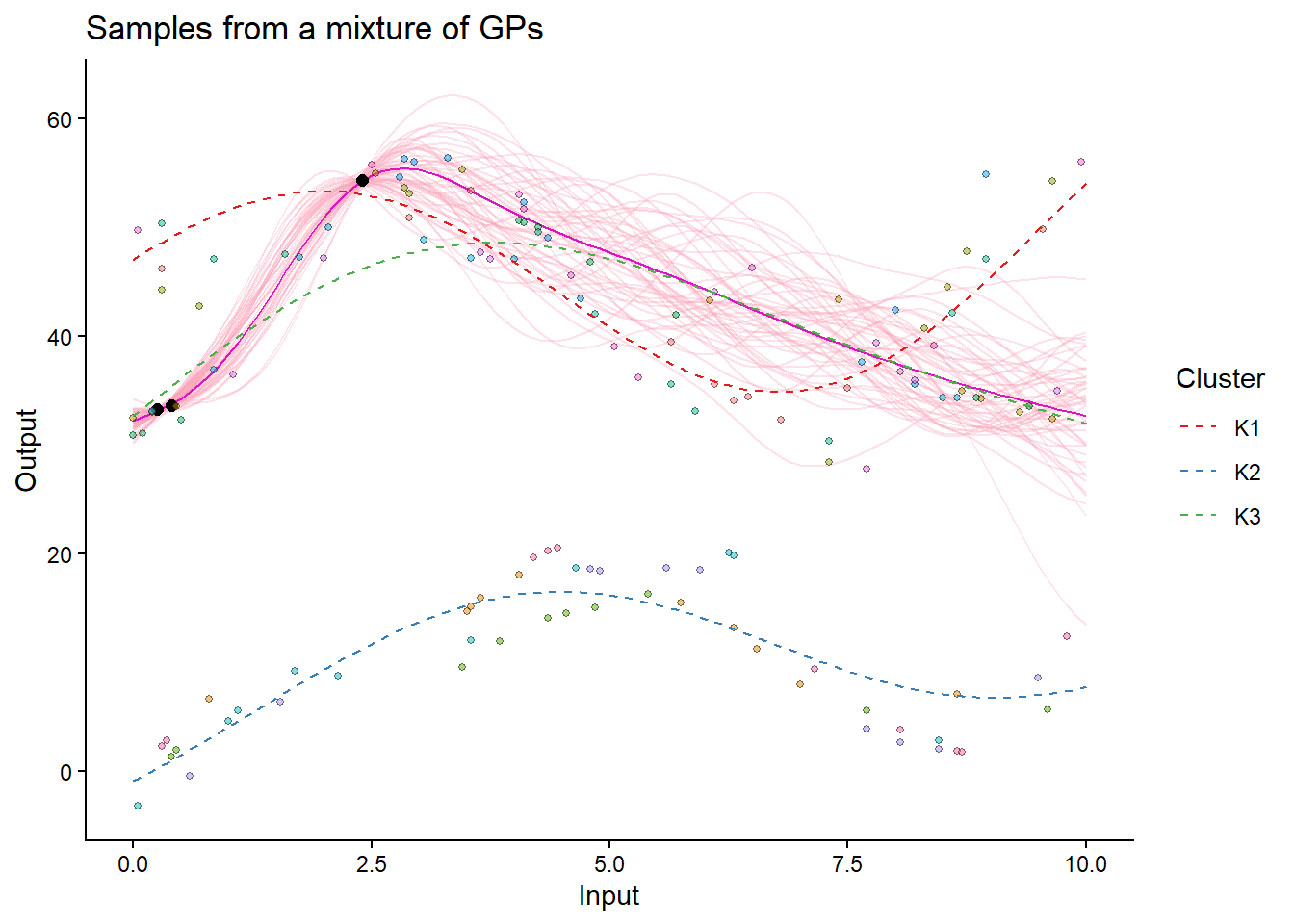
## Allocating tasks to clusters
train_data_clusters = data_allocate_cluster(trained_model = model_magmaclust)
## Visualizing the predictions
plot_magmaclust(
pred_complete,
data = pred_data,
data_train = train_data_clusters,
col_clust = TRUE,
prior_mean = model_magmaclust$hyperpost$mean,
samples = TRUE) +
geom_point(data = test_data, aes(x = Input, y = Output), color = "red", size = 2)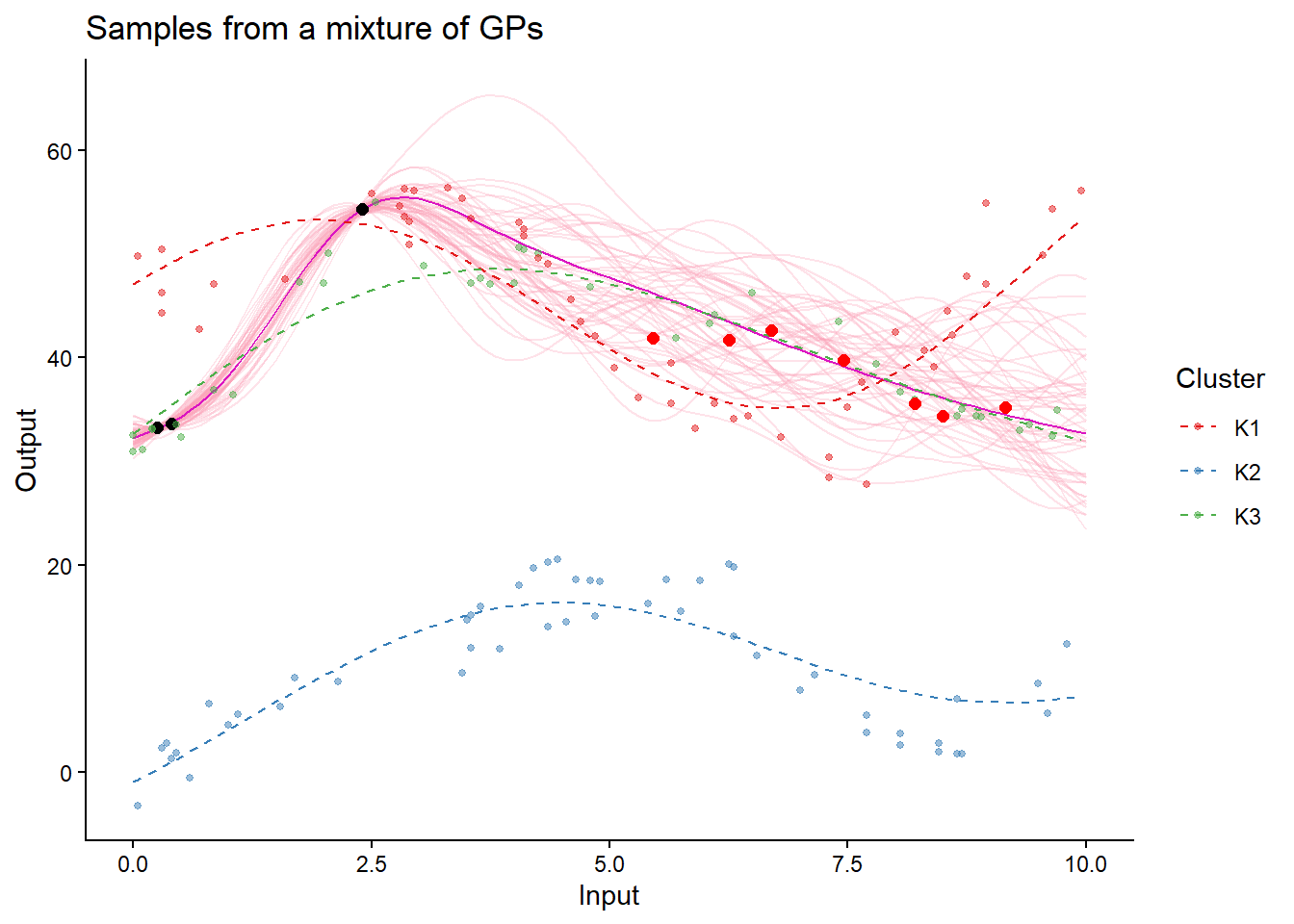
Jeu de données simulées en 2D
Nous allons maintenant considérer un jeu de données simulées en 2 dimensions, avec 3 clusters, 4 tâches par cluster, et 10 observations par tâche. Le code suivant permet de simuler et visualiser ces données :
library(tidyverse)
library(MagmaClustR)
set.seed(42)
data_2D = simu_db(M = 4, N = 10, K = 3, common_input = FALSE, covariate = TRUE)
data_2D# A tibble: 120 × 4
ID Input Covariate Output
<chr> <dbl> <dbl> <dbl>
1 ID1-Clust1 1.15 4 7.93
2 ID1-Clust1 2.3 1 9.45
3 ID1-Clust1 2.4 8.5 -2.84
4 ID1-Clust1 3.5 8 0.514
5 ID1-Clust1 4.4 1.5 22.5
6 ID1-Clust1 4.95 5 18.8
7 ID1-Clust1 5.45 6 17.0
8 ID1-Clust1 6.05 9.5 8.90
9 ID1-Clust1 6.35 7 20.9
10 ID1-Clust1 8.2 2 41.4
# ℹ 110 more rowsReprenez toutes les questions de l’exercice précédent (en ignorant celles concernant la visualisation), mais cette fois-ci en utilisant le jeu de données simulées en 2D. Vous devrez ajuster un modèle de mélange de processus gaussiens multi-tâches en choisissant 3 clusters, et effectuer des prédictions sur une tâche restante.
Dans le cas de données en 2 dimensions, la visualisation des données des prédictions peut être plus complexe. Vous pouvez vous contenter des sorties graphiques générées par défaut par la fonction pred_magmaclust(), qui affichent les prédictions sous forme de contours de heatmap.
## Splitting the data into training and test sets
list_ID_2D = unique(data_2D$ID)
train_data_2D = data_2D %>% filter(ID != list_ID_2D[1])
pred_data_2D = data_2D %>% filter(ID == list_ID_2D[1])
## Training the mixture of multi-task GP model
model_magmaclust_2D = train_magmaclust(data = train_data_2D, nb_cluster = 3)The 'ini_hp_i' argument has not been specified. Random values of hyper-parameters for the individual processes are used as initialisation.
The 'ini_hp_k' argument has not been specified. Random values of hyper-parameters for the mean processes are used as initialisation.
The 'prior_mean' argument has not been specified. The hyper_prior mean function is thus set to be 0 everywhere.
VEM algorithm, step 1: 2.79 seconds
Value of the elbo: -886.70321 --- Convergence ratio = Inf
VEM algorithm, step 2: 2.73 seconds
Value of the elbo: -838.83848 --- Convergence ratio = 0.05706
VEM algorithm, step 3: 1.92 seconds
Value of the elbo: -828.98191 --- Convergence ratio = 0.01189
VEM algorithm, step 4: 2.03 seconds
Value of the elbo: -825.61845 --- Convergence ratio = 0.00407
VEM algorithm, step 5: 1.89 seconds
Value of the elbo: -825.20586 --- Convergence ratio = 5e-04
The EM algorithm successfully converged, training is completed.
## Making predictions on the test data
pred_2D = pred_magmaclust(
data = pred_data_2D,
trained_model = model_magmaclust_2D)The hyper-posterior distribution of the mean process provided in 'hyperpost' argument isn't evaluated on the expected inputs. Start evaluating the hyper-posterior on the correct inputs...
The 'prior_mean_k' argument has not been specified. The hyper-prior mean functions are thus set to be 0 everywhere.
Done!
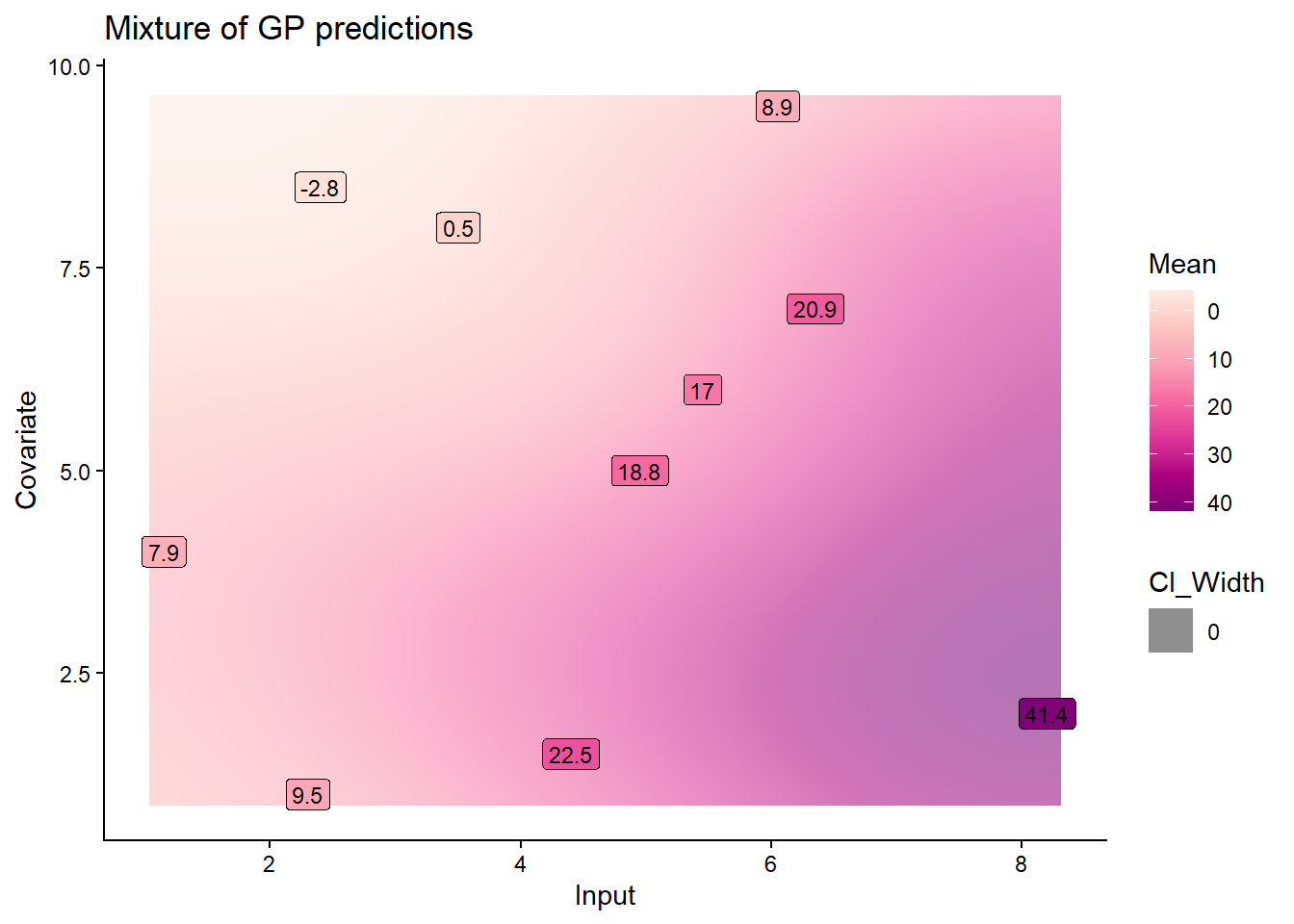
Données réelles
Pour terminer ce TP, nous allons utiliser un jeu de données réelles présente dans le package MagmaClustR. Il s’agit de poids d’enfants mesurés à différents âges entre 0 et 10 ans. L’objectif est de regrouper les enfants en fonction de leur courbe de croissance, et de prédire le poids futur à partir des observations passées.
Chargez les données réelles
weightprésentes dans le packageMagmaClustR, gardez un sous ensemble de 200 lignes, et formater les de sorte à être utilisable par les fonctions du package.Visualisez les données. Chaque enfant doit être représenté par une couleur différente.
Séparez les données en un jeu d’entrainement contenant toutes les observations de 80% des individus observés, et un jeu de test contenant les observations des 20% individus restants. Retirez également la moitié des observations du jeu de test pour la prédiction.
Ajustez un modèle de mélange de processus gaussiens multi-tâches en choisissant 2 clusters.
Pour un individu de test, visualisez la prédiction obtenue.
Effectuez des prédictions de trajectoires complètes pour l’ensemble des individus de test. Pour évaluer la qualité de prédiction globale, calculez l’erreur quadratique moyenne (RMSE) entre les valeurs prédites et les valeurs réelles pour l’ensemble des individus de test.
- Vous pouvez effectuer une boucle sur les individus de test pour effectuer les prédictions une par une, ou utiliser directement la fonction
pred_magmaclust()en fournissant l’ensemble des individus de test.
data = weight %>%
select(- sex) %>%
slice(1:200) %>%
as_tibble()
data# A tibble: 200 × 3
ID Input Output
<chr> <int> <dbl>
1 010-04004 0 2.82
2 010-04004 3 5.06
3 010-04004 6 6.62
4 010-04004 9 7.37
5 010-04004 12 7.52
6 010-04004 18 8.9
7 010-04004 36 11.1
8 010-04004 48 13.8
9 010-04004 60 16.4
10 010-04004 72 17.1
# ℹ 190 more rows## Splitting the data into training and test sets
set.seed(42)
list_ID_real = unique(data$ID)
train_ID_real = sample(list_ID_real, size = floor(0.8 * length(list_ID_real)))
test_ID_real = setdiff(list_ID_real, train_ID_real)
train_data_real = data %>% filter(ID %in% train_ID_real)
pred_data_real = data %>% filter(ID %in% test_ID_real, Input <= 12)
test_data_real = data %>% filter(ID %in% test_ID_real, Input > 12)
## Training the mixture of multi-task GP model
model_magmaclust_real = train_magmaclust(data = train_data_real, nb_cluster = 2)The 'ini_hp_i' argument has not been specified. Random values of hyper-parameters for the individual processes are used as initialisation.
The 'ini_hp_k' argument has not been specified. Random values of hyper-parameters for the mean processes are used as initialisation.
The 'prior_mean' argument has not been specified. The hyper_prior mean function is thus set to be 0 everywhere.
VEM algorithm, step 1: 3.39 seconds
Value of the elbo: -340.56798 --- Convergence ratio = Inf
VEM algorithm, step 2: 2.59 seconds
Value of the elbo: -308.06489 --- Convergence ratio = 0.10551
VEM algorithm, step 3: 4.69 seconds
Value of the elbo: -294.72447 --- Convergence ratio = 0.04526
VEM algorithm, step 4: 2.48 seconds
Value of the elbo: -288.36711 --- Convergence ratio = 0.02205
VEM algorithm, step 5: 2.48 seconds
Value of the elbo: -283.55437 --- Convergence ratio = 0.01697
VEM algorithm, step 6: 2.81 seconds
Value of the elbo: -276.94088 --- Convergence ratio = 0.02388
VEM algorithm, step 7: 1.97 seconds
Value of the elbo: -274.93306 --- Convergence ratio = 0.0073
VEM algorithm, step 8: 2.04 seconds
Value of the elbo: -274.03185 --- Convergence ratio = 0.00329
VEM algorithm, step 9: 2.03 seconds
Value of the elbo: -273.34955 --- Convergence ratio = 0.0025
VEM algorithm, step 10: 2.02 seconds
Value of the elbo: -272.84131 --- Convergence ratio = 0.00186
VEM algorithm, step 11: 1.99 seconds
Value of the elbo: -272.51739 --- Convergence ratio = 0.00119
VEM algorithm, step 12: 1.97 seconds
Value of the elbo: -272.28673 --- Convergence ratio = 0.00085
The EM algorithm successfully converged, training is completed.
## Visualizing the predictions for one test individual
pred_one = pred_data_real %>% filter(ID == test_ID_real[1])
test_one = test_data_real %>% filter(ID == test_ID_real[1])
pred_one_result = pred_magmaclust(
data = pred_one,
trained_model = model_magmaclust_real,
grid_inputs = seq(0, 75, 0.1))The hyper-posterior distribution of the mean process provided in 'hyperpost' argument isn't evaluated on the expected inputs. Start evaluating the hyper-posterior on the correct inputs...
The 'prior_mean_k' argument has not been specified. The hyper-prior mean functions are thus set to be 0 everywhere.
Done!
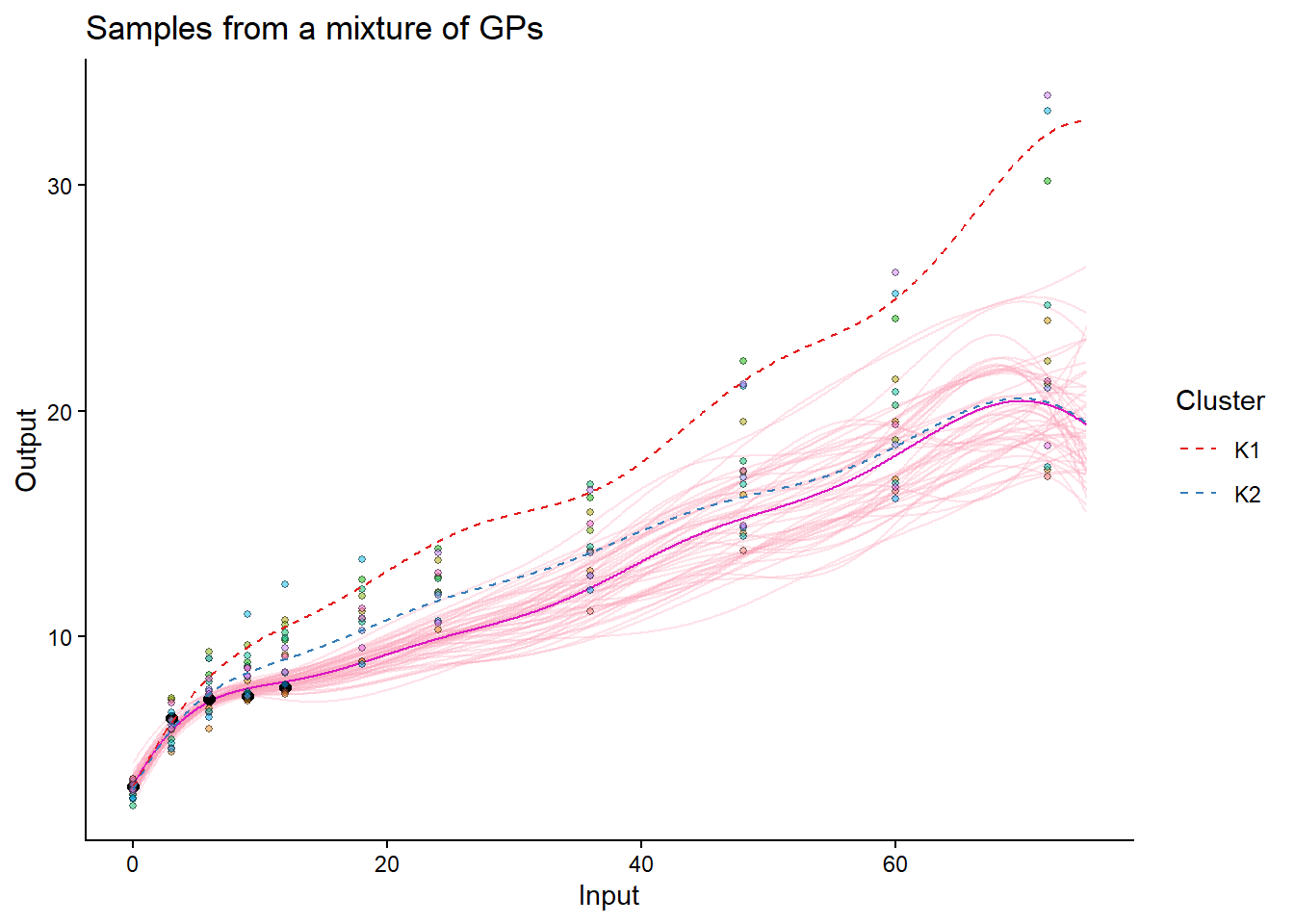
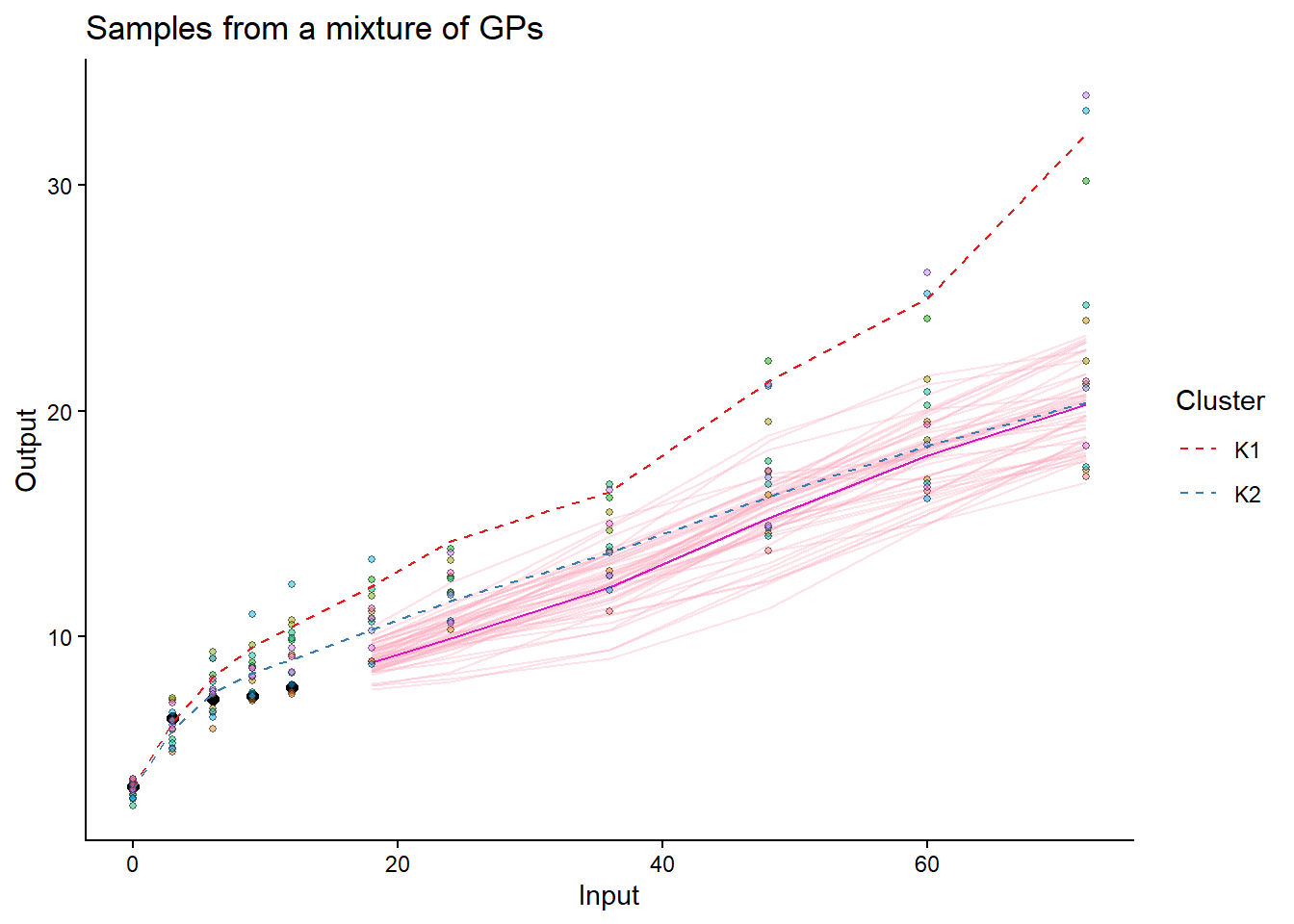
## Making predictions for all test individuals
for(i in seq_along(test_ID_real)) {
pred_i = pred_data_real %>% filter(ID == test_ID_real[i])
test_i = test_data_real %>% filter(ID == test_ID_real[i])
pred_i_result = pred_magmaclust(
data = pred_i,
trained_model = model_magmaclust_real,
grid_inputs = test_i$Input)
rmse_i = sqrt(mean((pred_i_result$mixture_pred$Mean - test_i$Output)^2))
cat("RMSE for individual", test_ID_real[i], ":", rmse_i, "\n")
}
RMSE for individual 010-04020 : 0.6606752 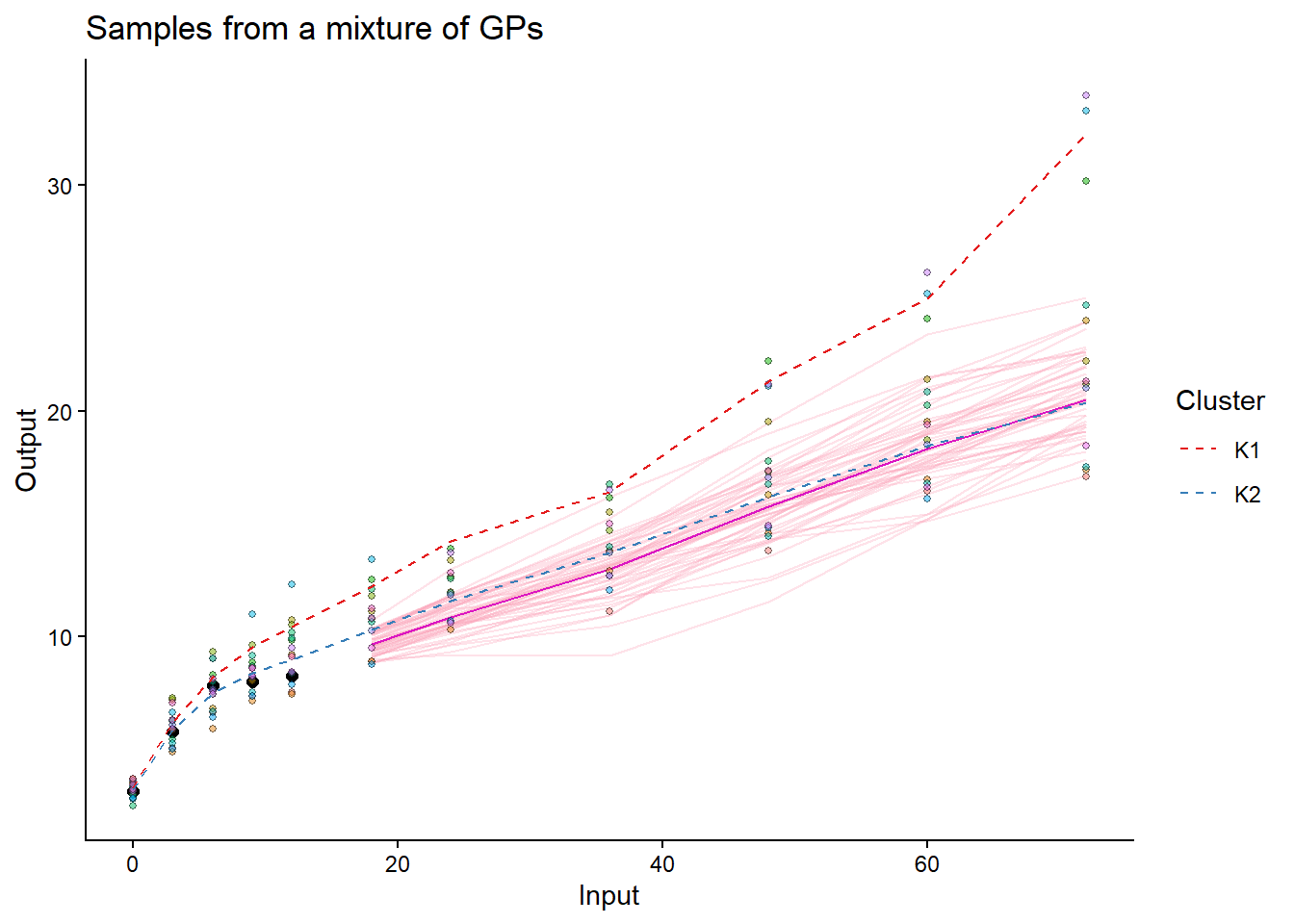
RMSE for individual 010-04082 : 0.876827 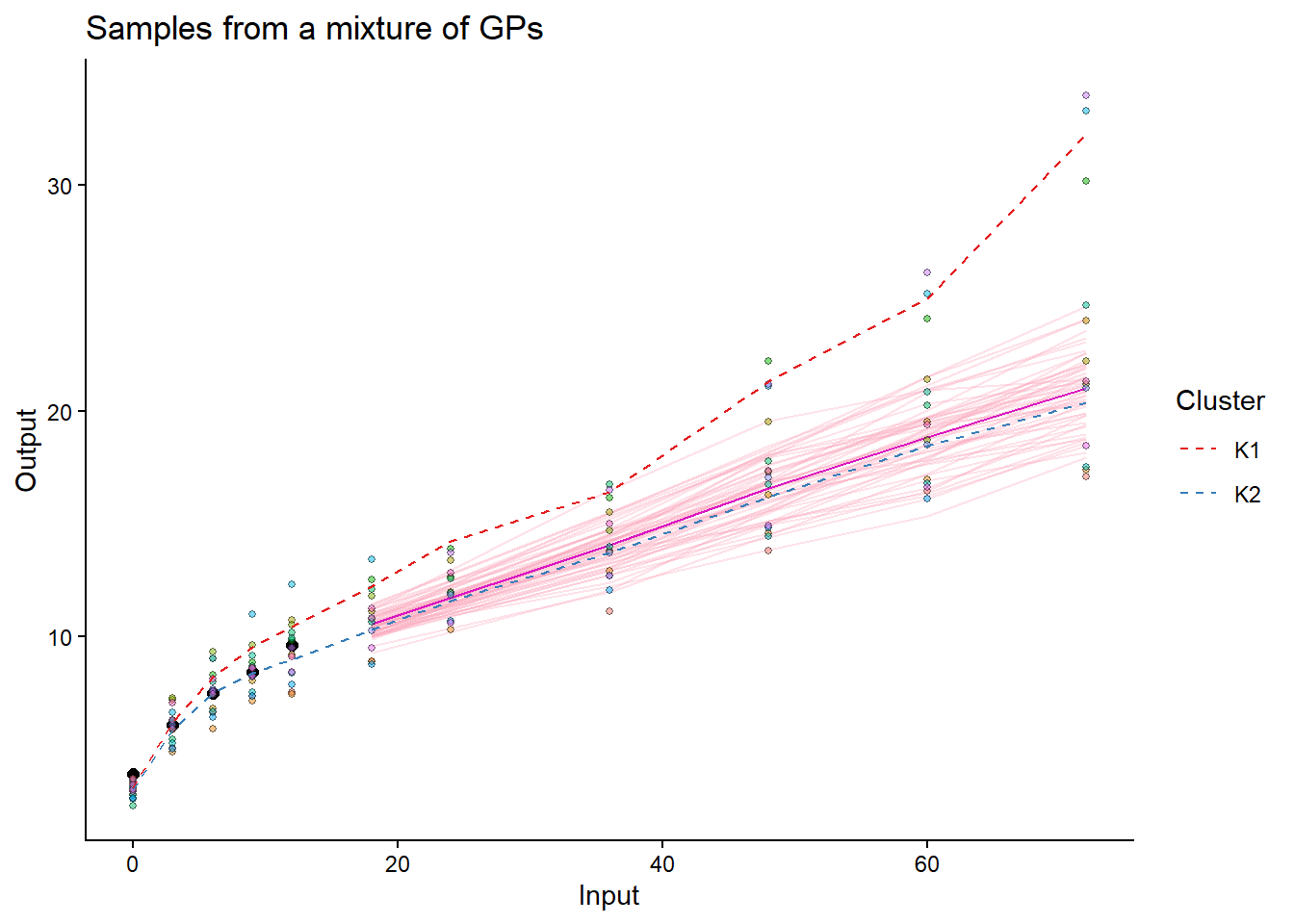
RMSE for individual 010-04102 : 4.485819 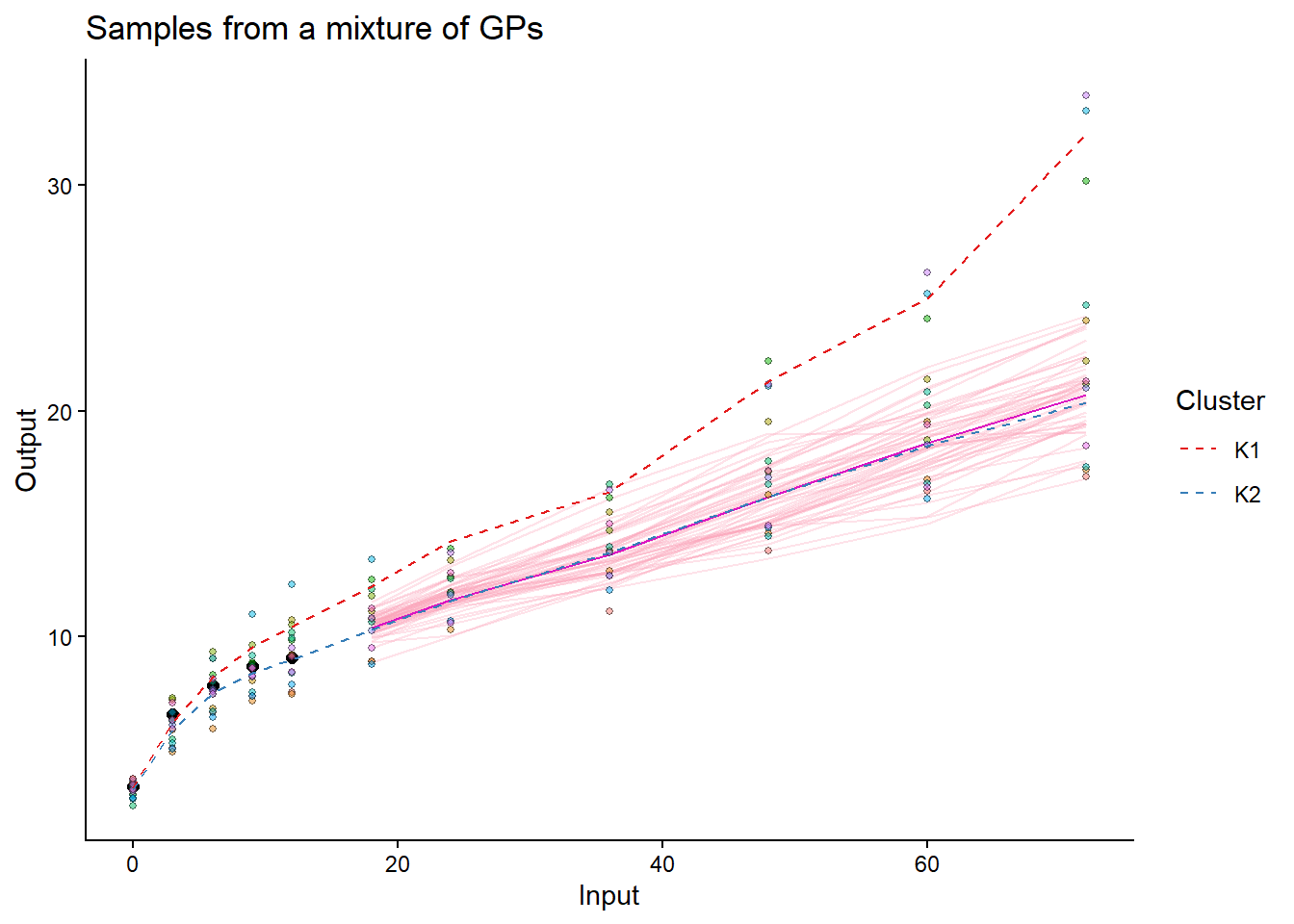
RMSE for individual 010-04110 : 2.245951