library(tidyverse)TP clusering : kmeans et modèles de mélanges gaussiens
Exercice 1 — Implémenter un k‑means “à la main” et visualiser les étapes
Pour illustrer l’algorithme k‑means, simulez un jeu de données 2D avec trois groupes bien séparés par exemple avec le code suivant :
set.seed(42)
# --- Données ---
X <- tibble(
x = c(rnorm(70,-3,0.6), rnorm(70,0,0.5), rnorm(70,3,0.6)),
y = c(rnorm(70,-1,0.6), rnorm(70,3,0.5), rnorm(70,0,0.6))
) %>% mutate(id = row_number())A présent, implémentez une fonction my_kmeans() pour l’algorithme des k-means en 3 étapes simples :
- Choisir K centres au hasard.
- Assigner chaque point au centre le plus proche.
- Recalculer les centres (moyenne des points assignés).
Gardez un historique des centres à chaque itération pour pouvoir les tracer ensuite.
N’hésitez pas à relancer plusieurs fois la fonctions pour observer la variabilité des résultats selon l’initialisation.
(Bonus) : réalisez un graphique avec la fonction facet_wrap() de ggplot2 pour visualiser l’évolution des centres au fil des itérations.
Pour un code minimal qui fonctionne, vous pouvez utiliser :
slice_sample()pour initialisationrowwise()etwhich.min()pour calculer les distancesgroup_by()+summarize()pour mettre à jour les centres
my_kmeans <- function(X, K, nb_iter = 10, plot = TRUE){
# initialize centers
centers <- X %>%
slice_sample(n = K) %>%
select(x,y) %>%
mutate(k = 1:K)
history <- centers %>% mutate(iter = 0)
for(it in 1:nb_iter){
# assign
assign <- X %>% rowwise() %>%
mutate(k = which.min((x - centers$x)^2 + (y - centers$y)^2)) %>%
ungroup()
# update
centers <- assign %>%
group_by(k) %>%
summarize(x = mean(x), y = mean(y), .groups='drop')
history <- centers %>%
mutate(iter = it) %>%
bind_rows(history)
}
if(plot){
# plot iterations
gg = ggplot() +
geom_point(data = assign, aes(x = x, y = y, colour = factor(k)), alpha = 0.6) +
geom_point(data = centers, aes(x = x, y = y, colour = factor(k)), size = 4) +
theme_classic()
print(gg)
}
list(data_clust = assign, centers = centers, history = history, plot = gg) %>%
return()
}
# run kmeans
set.seed(17)
res <- my_kmeans(X, K = 3, nb_iter = 5)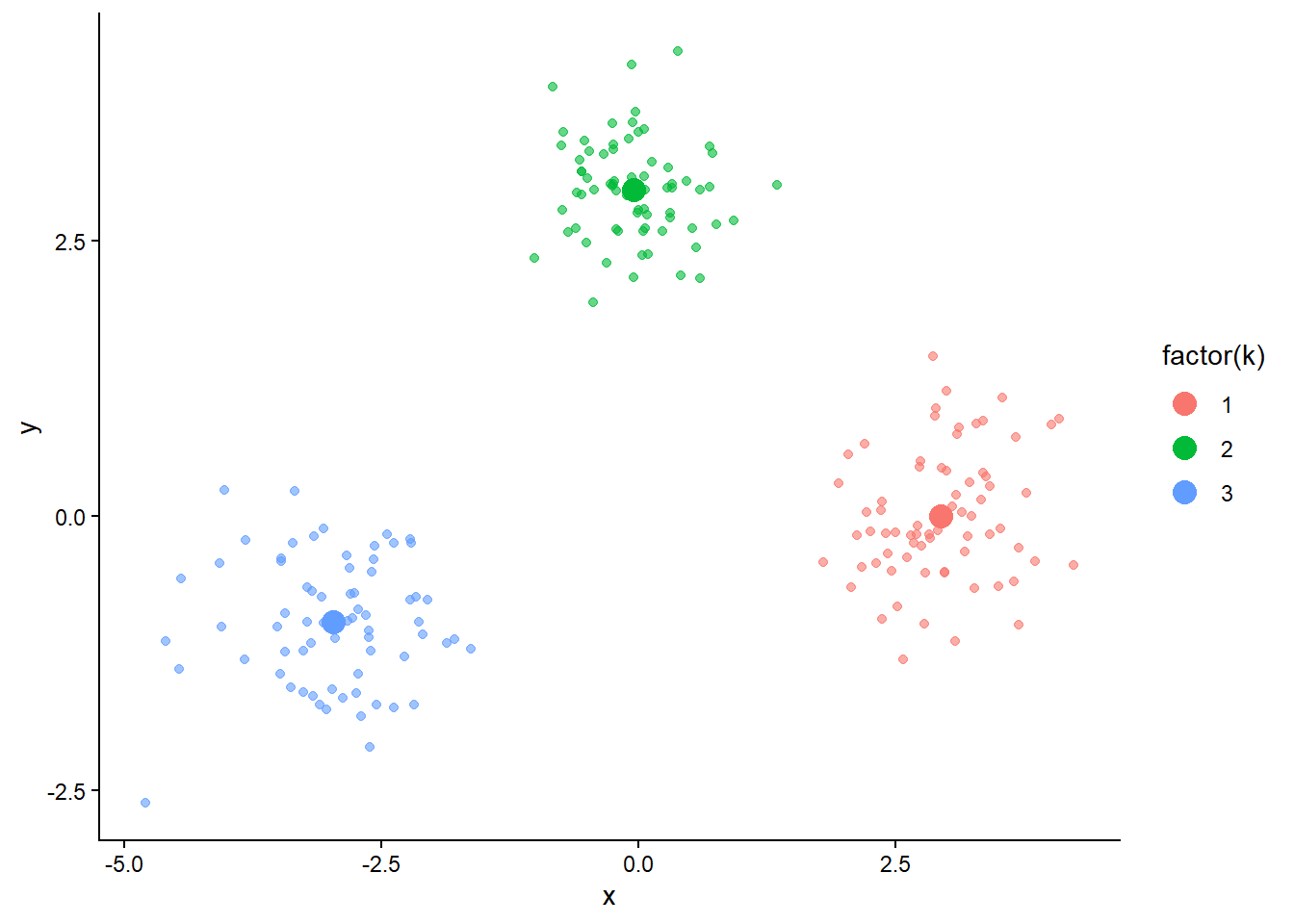
# plot history of centers
ggplot() +
geom_point(data = res$data_clust, aes(x = x, y = y, colour = factor(k)), alpha = 0.6) +
geom_point(data = res$history, aes(x = x, y = y, fill = factor(k)), shape = 21, size = 4) +
facet_wrap(~iter) +
labs(title = 'Itération:') +
theme_classic()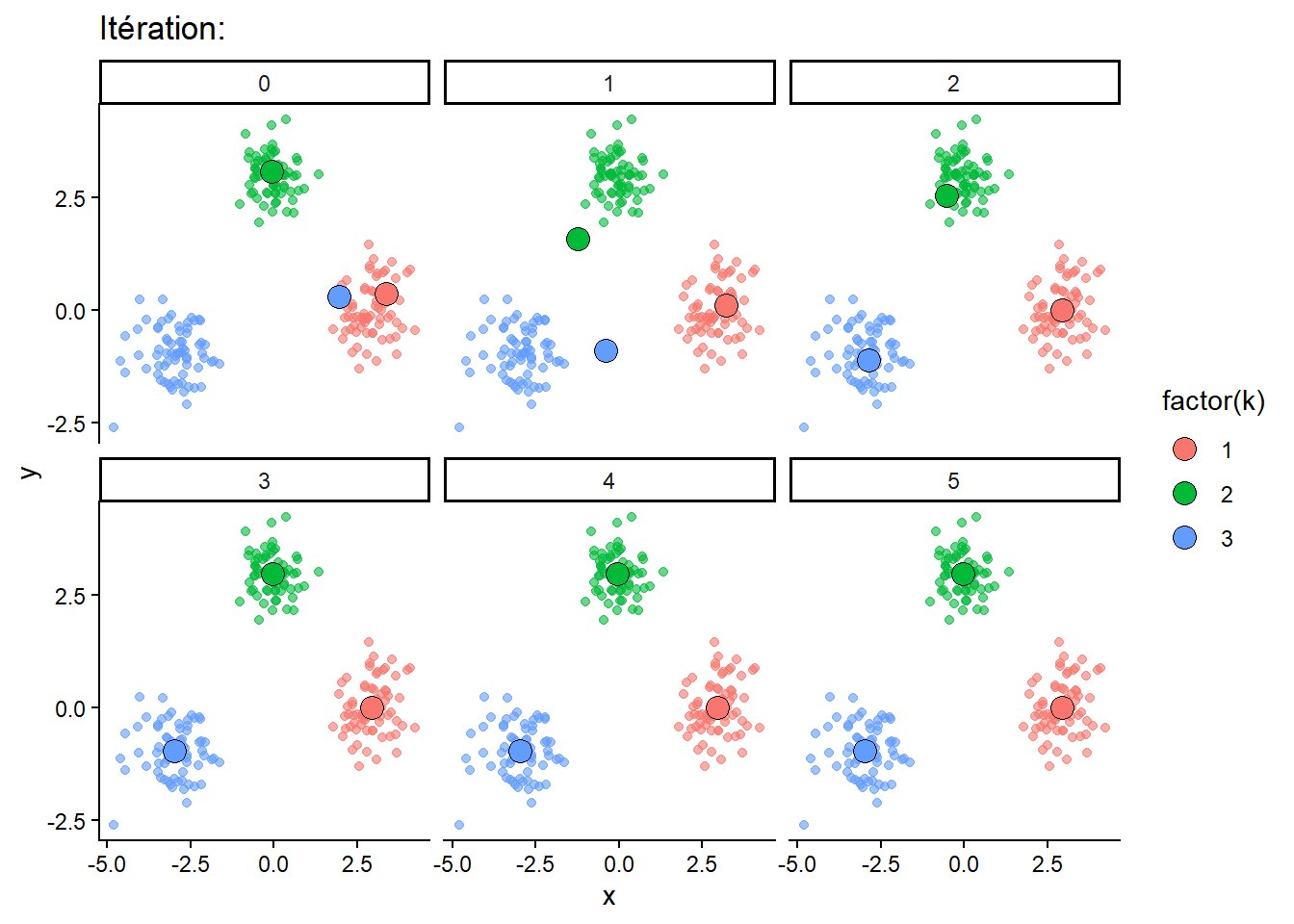
# rerun the kmeans to see variability
set.seed(2)
res2 <- my_kmeans(X, K = 3, nb_iter = 5)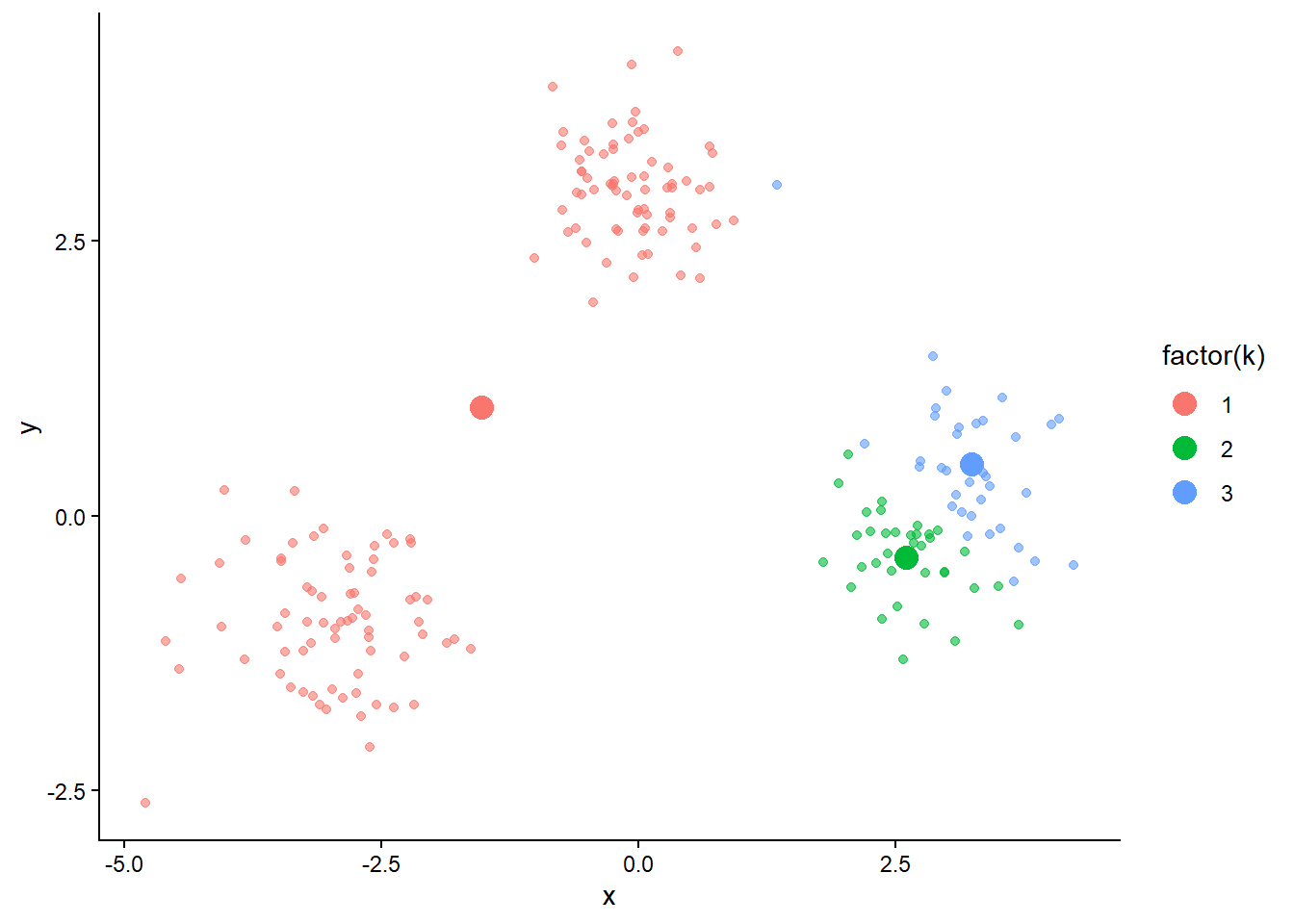
Exercice 2 — K‑means, mélange de Gaussiennes, soft vs hard clustering
On simule un jeu de données 2D avec deux groupes partiellement chevauchants :
set.seed(42)
# --- Données ---
df <- tibble(
x = c(rnorm(100,-1,1), rnorm(100,1,1)),
y = c(rnorm(100,1,1), rnorm(100,0,1))
)Appliquez l’algorithme k‑means (avec
kmeans()) pour obtenir un hard clustering (chaque point appartient à un seul cluster).Ensuite, utilisez la fonction
Mclust()du packagemclustpour ajuster un modèle de mélange gaussien (GMM) et obtenir un soft clustering (chaque point a une probabilité d’appartenance à chaque cluster).Tracez les résultats des deux méthodes avec
ggplot2:- Pour k‑means, colorez les points selon leur cluster assigné.
- Pour le GMM, colorez les points selon la probabilité d’appartenance au premier cluster (utilisez une échelle de couleur continue).
Pour obtenir un resultat robuste, utilisez plusieurs initialisations dans kmeans() (paramètre nstart). Pour le modèle de mélange (GMM), l’argument G de Mclust() permet de spécifier le nombre de composantes. Les probabilités d’appartenance sont dans l’attribut $z de l’objet retourné par Mclust().
## mclust is used to train a GMM
library(mclust)Warning: package 'mclust' was built under R version 4.4.3Package 'mclust' version 6.1.1
Type 'citation("mclust")' for citing this R package in publications.
Attaching package: 'mclust'The following object is masked from 'package:purrr':
map# k-means hard clustering
km <- kmeans(df, centers=2, nstart=20)
df_km <- df %>% mutate(cluster_km = factor(km$cluster))
# GMM soft clustering
gmm <- Mclust(df, G=2)
# Get membership probabilities in one cluster (soft clustering)
df_gmm <- df %>% mutate(prob1 = gmm$z[,1])
# Plot k-means
p1 <- ggplot(df_km, aes(x,y,color=cluster_km)) + geom_point() +
labs(title="k-means : hard clustering") + theme_minimal()
# Plot GMM
p2 <- ggplot(df_gmm, aes(x,y,color=prob1)) + geom_point() +
scale_color_gradientn(colours = c('pink', 'purple')) +
labs(title="GMM : soft clustering (probabilité 1er cluster)") + theme_minimal()
p1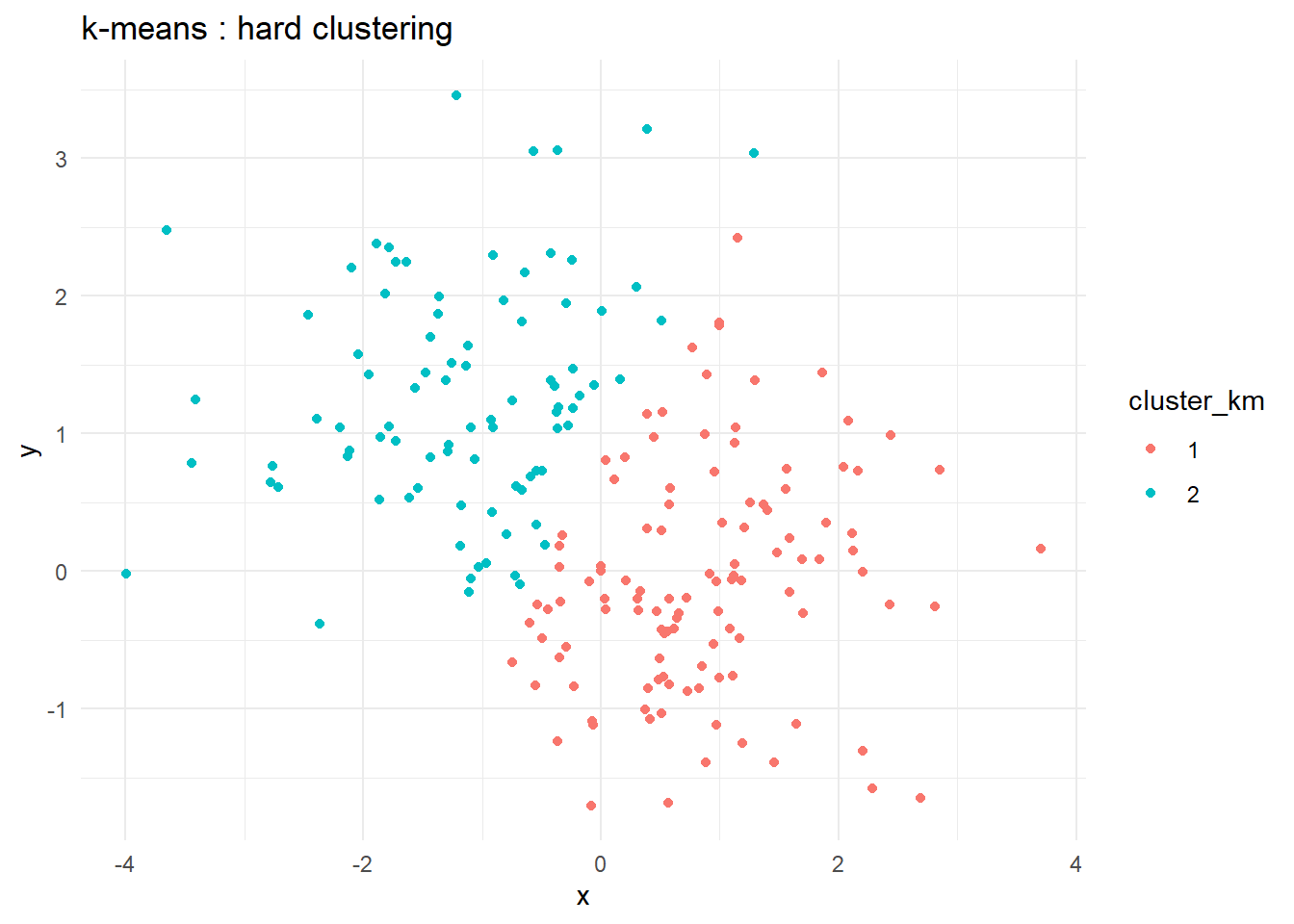
p2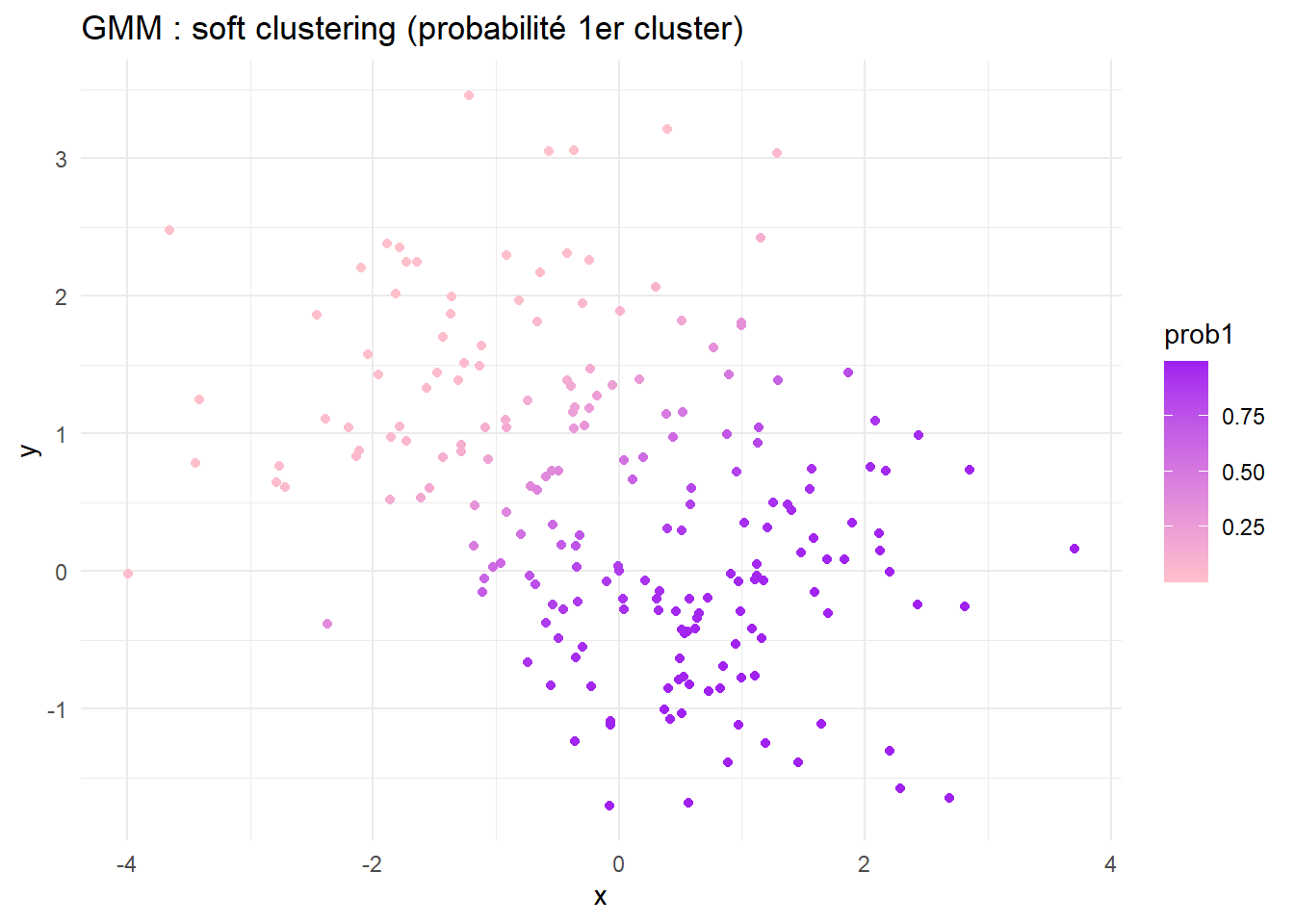
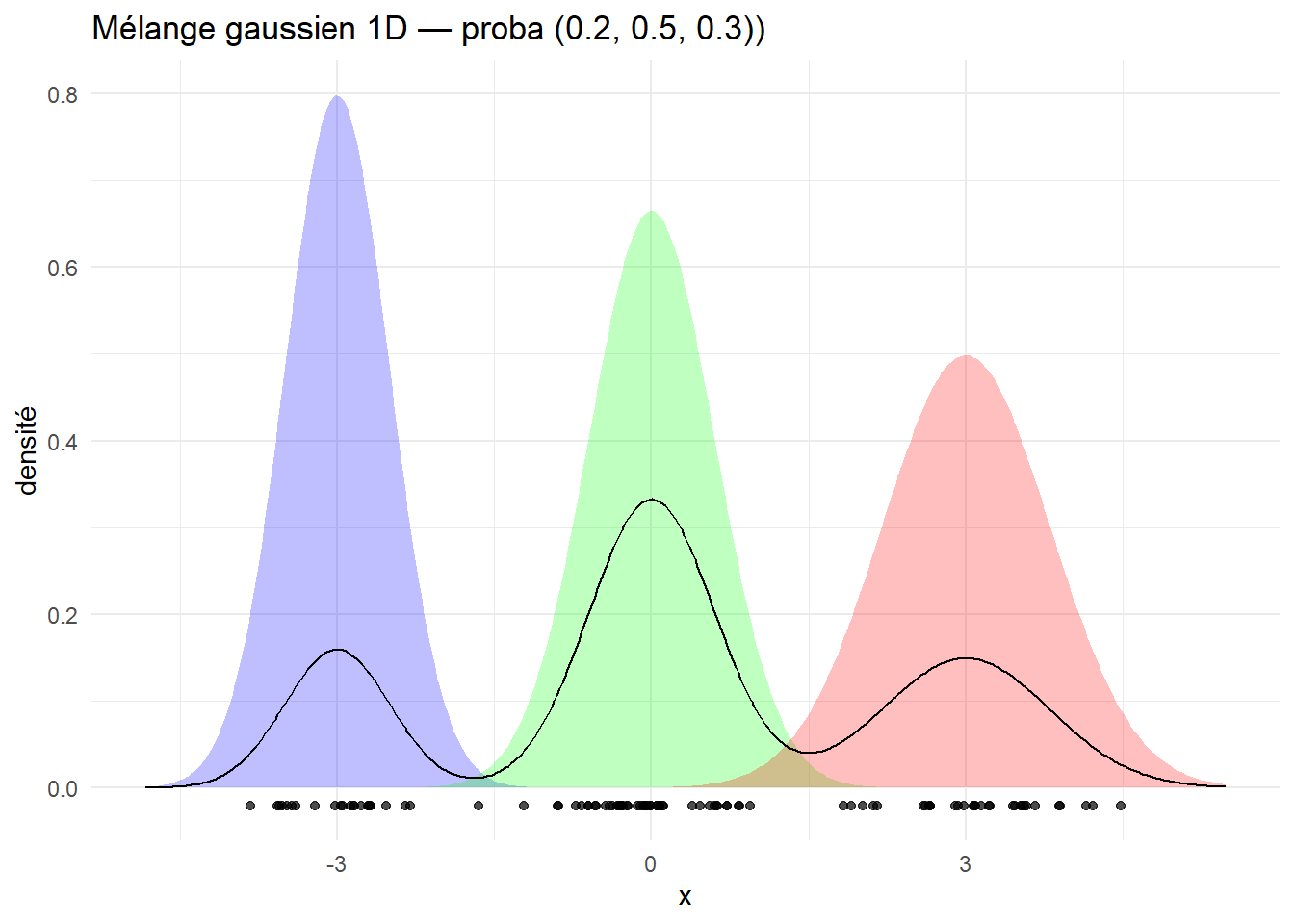
Exercice 3 — Introduction visuelle aux modèles de mélange gaussien (1D)
Simulez un mélange gaussien 1D à 3 composantes :
- proportions
pi = c(0.2,0.5,0.3), - moyennes
mu = c(-3,0,3), - écarts‑types
sd = c(0.5,0.6,0.8).
Puis tracez sur un même graphique :
- les densités des composantes individuelles,
- la densité du mélange,
- les données simulées (scatter plot).
Pour simuler les données, vous pouvez d’abord tirer les composantes latentes z selon les proportions pi, puis générer les observations Y en fonction de z. Pour tracer les densités, utilisez la fonction dnorm() pour chaque composante et calculez la densité du mélange comme une combinaison pondérée des densités des composantes.
set.seed(42)
# parameters of the mixture
pi <- c(0.2,0.5,0.3)
mu <- c(-3,0,3)
sd <- c(0.5,0.6,0.8)
# simulate data from the mixture
z <- sample(1:3, 100, replace = TRUE, prob = pi)
Y <- rnorm(100, mu[z], sd[z])
data <- tibble(y = Y)
# marginals and mixture densities
x <- seq(min(Y)-1, max(Y)+1, length.out = 400)
densities <- tibble(comp1 = dnorm(x, mu[1], sd[1]),
comp2 = dnorm(x, mu[2], sd[2]),
comp3 = dnorm(x, mu[3], sd[3])) %>%
mutate(mix = pi[1]*comp1 + pi[2]*comp2 + pi[3]*comp3) %>%
mutate(x = x)
# plot
ggplot(densities, aes(x = y)) +
geom_area(aes(x = x, y = comp1), alpha = 0.25, fill = 'blue', position = "identity") +
geom_area(aes(x = x, y = comp2), alpha = 0.25, fill = 'green', position = "identity") +
geom_area(aes(x = x, y = comp3), alpha = 0.25, fill = 'red', position = "identity") +
geom_line(aes(x = x, y = mix), color = "black") +
geom_point(data = data, aes(x = y, y = -0.02), alpha = 0.7) +
labs(title = "Mélange gaussien 1D — proba (0.2, 0.5, 0.3))",
x = "x", y = "densité") +
theme_minimal()