library(tidyverse)TP5 Clustering: Apprentissage par processus Gaussiens
Rappels : Processus Gaussiens
Un processus gaussien est une généralisation de la distribution gaussienne à des fonctions. Il est défini par une moyenne et une fonction de covariance. Soit \(f(x)\) une fonction aléatoire, un processus gaussien est noté \(f(x) \sim GP(m(x), k(x, x'))\), où \(m(x)\) est la fonction de moyenne et \(k(x, x')\) est la fonction de covariance (ou noyau).
La fonction de moyenne \(m(x)\) est souvent choisie comme étant nulle pour simplifier les calculs, mais elle peut être définie autrement en fonction des besoins spécifiques du problème. La fonction de covariance \(k(x, x')\) définit la similarité entre les points d’entrée \(x\) et \(x'\). Une fonction de covariance couramment utilisée est le noyau exponentiel quadratique (SE) : \[k(x, x') = \sigma_f^2 \exp\left(-\frac{(x - x')^2}{2l^2}\right)\] où \(\sigma_f^2\) est la variance de la fonction et \(l\) est la longueur d’échelle, contrôlant la “smoothness” de la fonction.
La vraisemblance d’un processus gaussien est donnée par : \[p(y | \textbf{x}, \theta) = \mathcal{N}(y | m(\textbf{x}), K(\textbf{x}, \textbf{x}) + \sigma_n^2 I)\]
où \(y\) est le vecteur des observations, \(\textbf{x}\) est la matrice des entrées, \(\theta\) représente les hyperparamètres du modèle, \(K(\textbf{x}, \textbf{x})\) est la matrice de covariance calculée à partir de la fonction de covariance, \(\sigma_n^2\) est la variance du bruit, et \(I\) est la matrice identité.
La formule de prédiction pour un nouveau point \(x_*\) est donnée par : \[p(f_* | x_*, \textbf{x}, y) = \mathcal{N}(f_* | \mu_*, \sigma_*^2)\]
avec
- \(\mu_* = m(x_*) + K(x_*, \textbf{x})[K(\textbf{x}, \textbf{x}) + \sigma_n^2 I]^{-1}(y - m(\textbf{x}))\)
- \(\sigma_*^2 = K(x_*, x_*) - K(x_*, \textbf{x})[K(\textbf{x}, \textbf{x}) + \sigma_n^2 I]^{-1}K(\textbf{x}, x_*)\)
Définition du noyau de covariance
Définir une fonction
kern_se()qui implémente le noyau exponentiel quadratique (RBF) entre deux vecteursx1etx2, avec des hyperparamètressigma_fetl.Définir maintenant une fonction
matrix_se(), appelantkern_se(), qui construit la matrice de covariance complète pour un ensemble de points d’entréex, et des hyperparamètressigma_fetl.Utiliser cette fonction pour construire la matrice de covariance
Kpour un ensemble de points d’entréexallant de -5 à 5 avec un pas de 0.1. Vous pouvez par exemple fixer les valeurs des hyperparamètressigma_f = 1etl = 1.
Pour remplir la matrice de covariance, vous pouvez utiliser une double boucle for pour itérer sur chaque paire de points dans x et appliquer la fonction kern_se().
# Définition du noyau exponentiel quadratique
kern_se <- function(x1, x2, sigma_f, l) {
sqdist <- (x1 - x2)^2
return(sigma_f^2 * exp(-0.5 * sqdist / l^2))
}
# Construction de la matrice de covariance complète
matrix_se <- function(x, sigma_f, l, x2 = NULL) {
n <- length(x)
# Si x2 n'est pas fourni, on utilise x pour construire une matrice carrée
if (is.null(x2)) {
x2 <- x
}
n2 <- length(x2)
# Initialisation de la matrice de covariance
K <- matrix(0, n, n2)
# Remplissage de la matrice de covariance
for (i in 1:n) {
for (j in 1:n2) {
K[i, j] <- kern_se(x[i], x2[j], sigma_f, l)
}
}
return(K)
}
# Exemple d'utilisation
x <- seq(-5, 5, by = 0.1)
sigma_f <- 1
l <- 1
K <- matrix_se(x, sigma_f, l)
# Affichage d'un sous bloc la matrice de covariance
K[1:5, 1:5] [,1] [,2] [,3] [,4] [,5]
[1,] 1.0000000 0.9950125 0.9801987 0.9559975 0.9231163
[2,] 0.9950125 1.0000000 0.9950125 0.9801987 0.9559975
[3,] 0.9801987 0.9950125 1.0000000 0.9950125 0.9801987
[4,] 0.9559975 0.9801987 0.9950125 1.0000000 0.9950125
[5,] 0.9231163 0.9559975 0.9801987 0.9950125 1.0000000# Visualisation de la matrice de covariance
library(reshape2)
K_melt <- melt(K)
ggplot(K_melt, aes(Var1, Var2, fill = value)) +
geom_tile() +
scale_fill_viridis_c() +
labs(title = "Matrice de Covariance K", x = "Index", y = "Index") +
ylim(100, 0) +
theme_classic()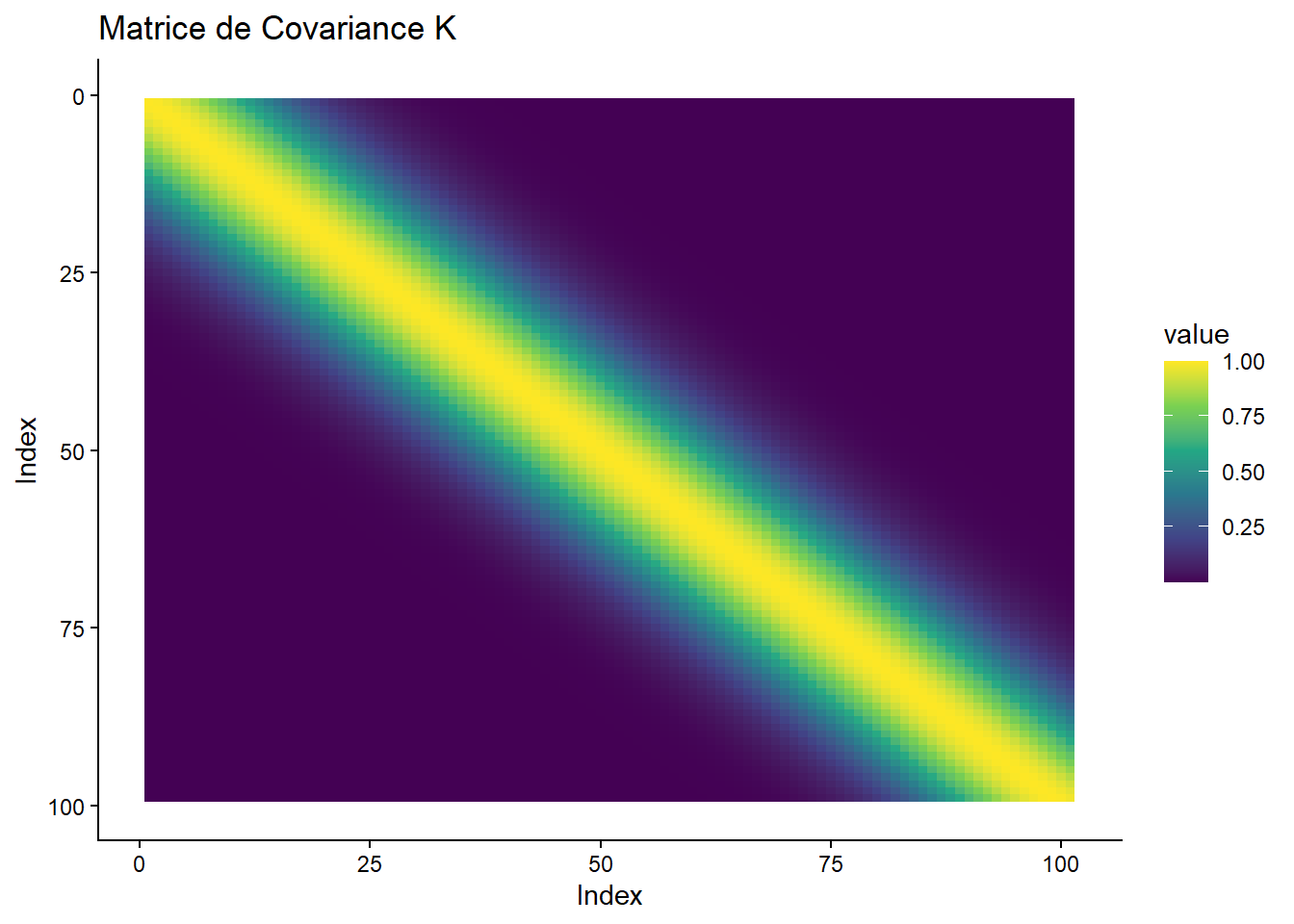
Echantillonnage à partir d’un processus gaussien
Utiliser la matrice de covariance
Kdéfinie précédemment pour échantillonner des fonctions à partir d’un processus gaussien. Vous pouvez utiliser la fonctionmvrnorm()du packageMASSpour cela. Echantillonner 5 fonctions différentes.Visualiser les fonctions échantillonnées sur le même graphique.
Pour échantillonner des fonctions à partir d’un processus gaussien, vous pouvez utiliser la fonction mvrnorm(n, mu, Sigma) où n est le nombre d’échantillons, mu est le vecteur de moyenne (souvent un vecteur de zéros), et Sigma est la matrice de covariance.
Pour visualiser les fonctions, vous pouvez utiliser ggplot2 en transformant les données en format long avec pivot_longer().
library(MASS)
set.seed(42)
# Nombre d'échantillons
n_samples <- 5
# Vecteur de moyenne (zéro)
mu <- rep(0, length(x))
# Echantillonnage à partir du processus gaussien
samples <- mvrnorm(n_samples, mu, K)
# Transformation des données pour ggplot
samples_df <- t(samples) %>%
as_tibble() %>%
mutate(x = x) %>%
pivot_longer(cols = -x, names_to = "sample", values_to = "value")
# Visualisation des fonctions échantillonnées
ggplot(samples_df, aes(x = x, y = value, color = sample)) +
geom_line() +
labs(title = "Echantillons de fonctions à partir d'un processus gaussien",
x = "x", y = "f(x)") +
theme_classic()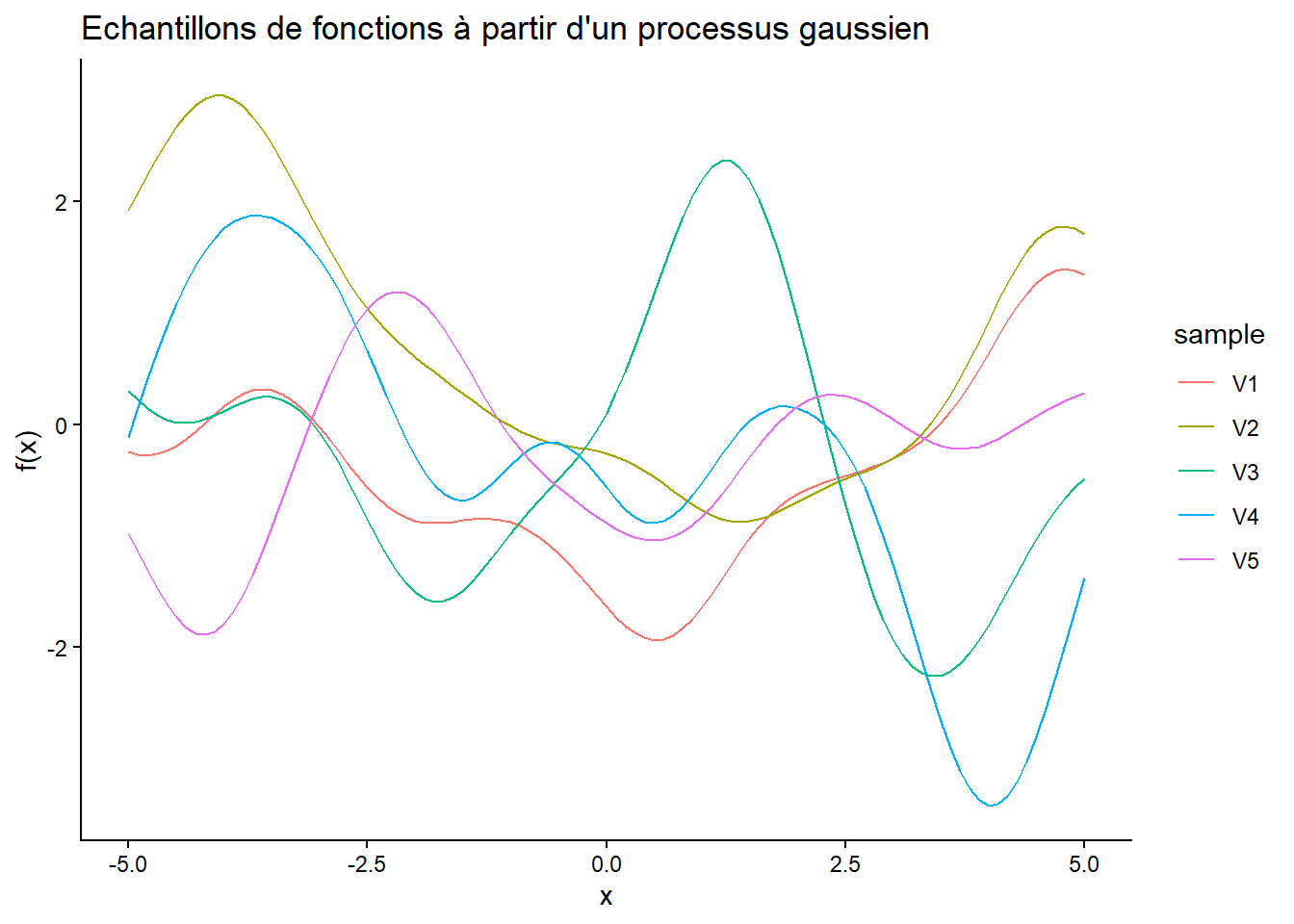
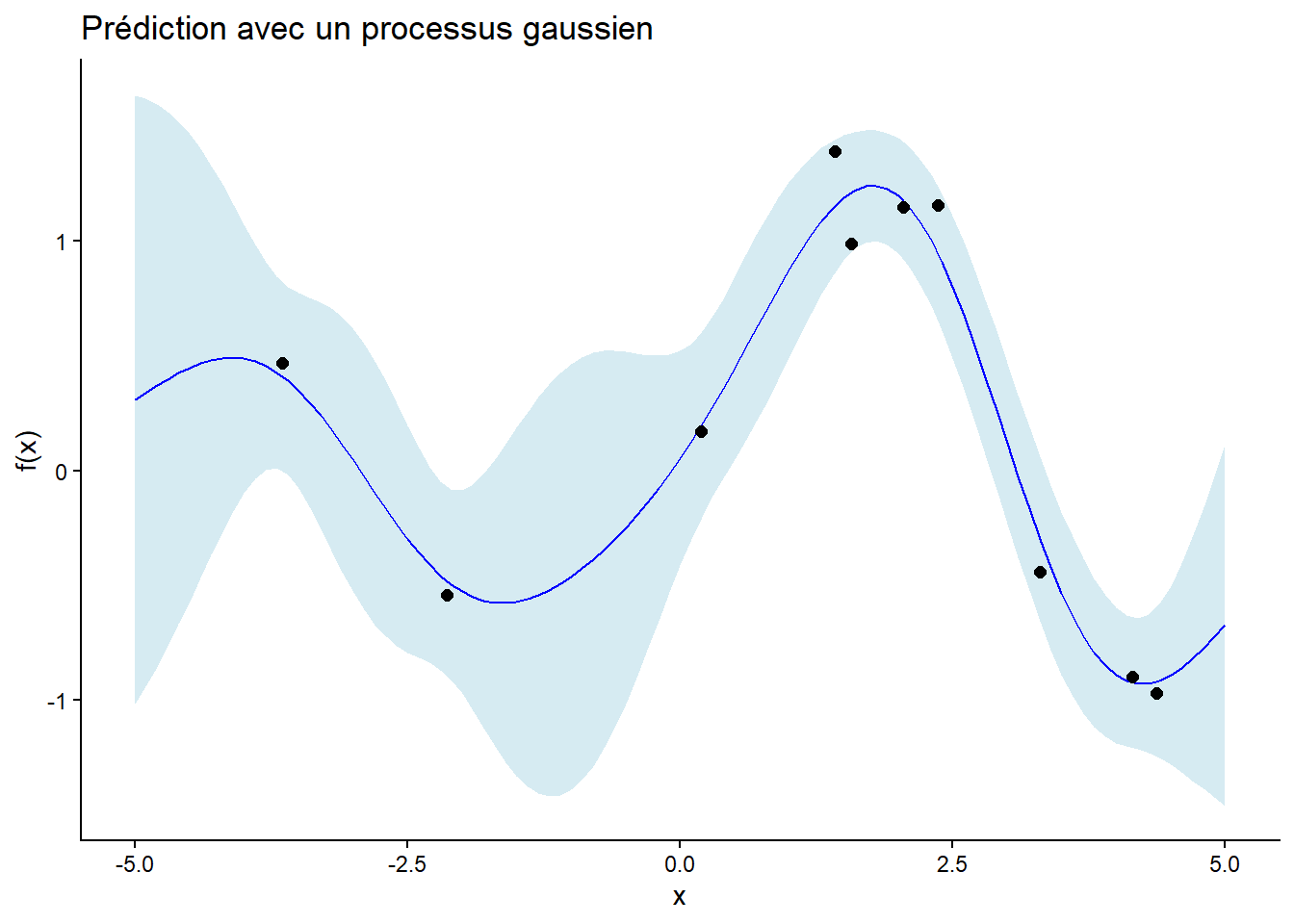
Prédiction avec un processus gaussien
Générer des données d’entraînement en échantillonnant 10 points aléatoires dans l’intervalle [-5, 5] et en évaluant une fonction sinusoïdale avec du bruit gaussien.
Utiliser le processus gaussien pour prédire les valeurs de la fonction à de nouveaux points d’entrée dans l’intervalle [-5, 5]. Calculer la moyenne prédite et la covariance associée. Définir une fonction
gp_predict()pour effectuer la prédiction.Visualiser les données d’entraînement, la moyenne prédite, et les intervalles de confiance (par exemple, ±2 écarts-types). Définir une fonction
plot_gp_predict()pour effectuer la visualisation.
Pour générer les données d’entraînement, vous pouvez utiliser runif() pour les points d’entrée et rnorm() pour le bruit. Pour la prédiction, vous devrez calculer la moyenne et la covariance en utilisant les formules de prédiction des processus gaussiens. Pour visualiser les résultats, vous pouvez utiliser ggplot2.
set.seed(42)
# Génération des données d'entraînement
n_train <- 10
x_train <- sort(runif(n_train, -5, 5))
y_train <- sin(x_train) + rnorm(n_train, 0, 0.2)
train_df <- tibble(x = x_train, y = y_train)
# Fonction de prédiction du processus gaussien
gp_predict <- function(train_df, x_test, prior_mean = 0, sigma_f, l, sigma_n) {
K <- matrix_se(train_df$x, sigma_f, l) + sigma_n^2 * diag(length(x_train))
K_s <- matrix_se(x_test, sigma_f, l, train_df$x)
K_ss <- matrix_se(x_test, sigma_f, l)
K_inv <- solve(K)
mu_s <- prior_mean + K_s %*% K_inv %*% (train_df$y - prior_mean)
cov_s <- K_ss - K_s %*% K_inv %*% t(K_s)
return(list(x = x_test, mu = mu_s, cov = cov_s))
}
plot_gp_predict <- function(pred, train_df){
x_test <- pred$x
mu_s <- pred$mu
cov_s <- pred$cov
# Calcul des intervalles de confiance
std_s <- sqrt(diag(cov_s))
upper <- mu_s + 2 * std_s
lower <- mu_s - 2 * std_s
# Visualisation des résultats
pred_df <- tibble(x = x_test, mu = mu_s, upper = upper, lower = lower)
ggplot() +
geom_ribbon(data = pred_df, aes(x = x, ymin = lower, ymax = upper), fill = "lightblue", alpha = 0.5) +
geom_line(data = pred_df, aes(x = x, y = mu), color = "blue") +
geom_point(data = train_df, aes(x = x, y = y), size = 2) +
labs(title = "Prédiction avec un processus gaussien",
x = "x", y = "f(x)") +
theme_classic()
}
# Points de test pour la prédiction
x_test <- seq(-5, 5, by = 0.1)
sigma_f <- 1
l <- 3
sigma_n <- 0.1
prior_mean = 0
pred <- gp_predict(train_df, x_test, prior_mean, sigma_f, l, sigma_n)
plot_gp_predict(pred, train_df)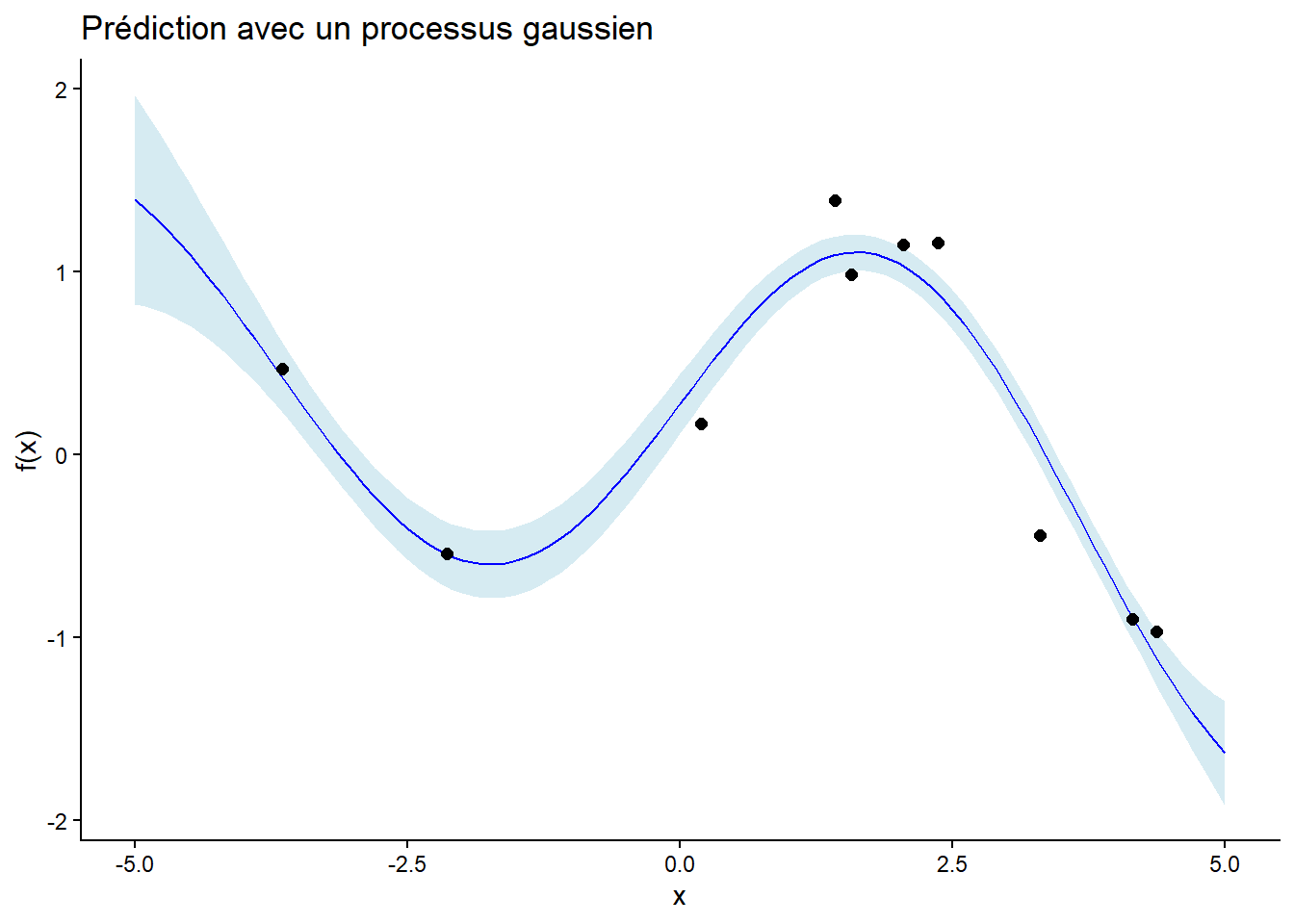
Optimisation des hyperparamètres
Tester les fonctions de prédiction et de plot avec différentes valeurs de
prior_meanet d’hyperparamètressigma_f,l, etsigma_npour observer leur impact sur les prédictions.Définir une fonction
neg_logL()qui calcule la log-vraisemblance marginale négative pour un ensemble de données d’entraînement donné et des hyperparamètressigma_f,l, etsigma_n.Utiliser une méthode d’optimisation (par exemple,
optim()) pour trouver les hyperparamètres qui minimisent cette log-vraisemblance marginale.
Pour la log-vraisemblance marginale négative, on rappelle la formule : \[-\log p(y | \textbf{x}, \theta) = \frac{1}{2} y^T K^{-1} y + \frac{1}{2} \log |K| + \frac{n}{2} \log 2\pi\]
La fonction optim() peut être utilisée pour minimiser cette fonction en fournissant des valeurs initiales pour les hyperparamètres.
set.seed(42)
# Fonction de log-vraisemblance marginale négative
neg_logL <- function(hp, train_df) {
sigma_f <- exp(hp[1])
l <- exp(hp[2])
sigma_n <- exp(hp[3])
n <- nrow(train_df)
K <- matrix_se(train_df$x, sigma_f, l) + sigma_n^2 * diag(n)
logL <- -0.5 * t(train_df$y) %*% solve(K) %*% train_df$y - 0.5 * log(det(K)) - (n / 2) * log(2 * pi)
return(-logL)
}
# Optimisation des hyperparamètres
init_hp <- log(c(1, 1, 0.1)) # Valeurs initiales en log-échelle
opt_result <- optim(init_hp, neg_logL, train_df = train_df, method = "L-BFGS-B")
opt_hp <- exp(opt_result$par)
cat("Optimized hyperparameters:", opt_hp,"\n")Optimized hyperparameters: 0.7579234 1.110897 0.2151907 # Prédiction avec les hyperparamètres optimisés
pred_opt <- gp_predict(train_df, x_test, prior_mean, opt_hp[1], opt_hp[2], opt_hp[3])
plot_gp_predict(pred_opt, train_df)