library(tidyverse)TP4 Clustering: Algorithme EM et mélange de Gaussiennes
Rappels : Modèle de mélange gaussien et log-vraisemblance complète
On rappelle que le modèle de mélange Gaussien pour \(X = \{x_i\}_{i=1}^n \in \mathbb{R}\) i.i.d a pour densité de probabilité : \[\begin{equation} p_\theta(x) = \sum_{k=1}^K \pi_k \mathcal{N}(x \mid \mu_k, \sigma_k^2) \end{equation}\] Les paramètres du modèle sont \(\theta = \{\pi_k, \mu_k, \sigma_k^2\}\), avec \(\sum_l \pi_l = 1\).
Ce cadre est un cas particulier modèle à variables latentes discrètes telles que \(Z = \{z_i\}_{i=1}^n\), avec \(z_i \in \{0,1\}^K\) un vecteur binaire encodant l’appartenance de l’observation \(x_i\) à un cluster \(k\). De plus, on rappelle:
Note 1: Equations importantes
- la log-vraisemblance complète des observations et des variables latentes \[\begin{equation*} \log p_\theta(X,Z) = \sum_{i=1}^n \sum_{k=1}^K {z_{ik} \left[ \log \pi_k + \log \mathcal{N}(x_i \mid \mu_k, \sigma_k^2) \right]} \end{equation*}\]
- la probabilité a posteriori d’appartenir au cluster \(k\) pour l’observation \(x_i\) (formule de la E-step) : \[\begin{equation*} \tau_{ik} = p(z_{ik} =1 \mid x_i, \theta) = \frac{\pi_k \mathcal{N}(x_i, \mu_k, \sigma_k^2)}{\sum_l \pi_l \mathcal{N}(x_i, \mu_l, \sigma_l^2)} \end{equation*}\]
- les estimateurs du maximum de vraisemblance (formules de la M-step): \[\begin{equation*} \hat{\pi}_k = \frac{1}{n} \sum_{i=1}^n \tau_{ik}, \quad \hat{\mu}_k = \frac{\sum_{i=1}^n \tau_{ik} x_i}{\sum_{i=1}^n \tau_{ik}}, \quad \hat{\sigma}^2_k = \frac{\sum_{i=1}^n \tau_{ik} (x_i - \hat{\mu}_k)^2}{\sum_{i=1}^n \tau_{ik}} \end{equation*}\]
Implémentation de l’algorithme EM pour un mélange de Gaussiennes 1D
Le but de cet exercice pratique est d’implémenter votre propre algorithme EM, pas à pas. Nous utiliserons pour le jeu de données synthétique suivant.
data <- tibble(Var=c(-3.3,-4.4,-1.9,3.3,2.5,3.2,0.3,0.1,-0.1,-0.5),
partition1=c(1,1,1,2,2,2,2,2,1,1),
partition2=c(1,3,2,1,3,2,1,3,2,1)
)
data # A tibble: 10 × 3
Var partition1 partition2
<dbl> <dbl> <dbl>
1 -3.3 1 1
2 -4.4 1 3
3 -1.9 1 2
4 3.3 2 1
5 2.5 2 3
6 3.2 2 2
7 0.3 2 1
8 0.1 2 3
9 -0.1 1 2
10 -0.5 1 1Visualisation des partitions initiales
Ecrivez une fonction plot_data(x, partition) qui affiche les points \(x\) en 1D, colorés selon la partition donnée en argument. Pensez-vous qu’une de ces partitions est meilleure que l’autre pour initialiser l’algorithme EM ?
Pour afficher les points en 1D, vous pouvez utiliser ggplot2 avec geom_point(), en mappant la couleur des points à la variable de partition.
library(ggplot2)
plot_data <- function(x, partition) {
# function that plot the 1D data vector x with color
# according to an argument partition
#
# return: a ggplot graph
gg = ggplot(tibble(x = x, group = factor(partition))) +
geom_point(aes(x=x, y = 0, color=group)) +
theme_classic()
return(gg)
}
plot_data(data$Var, data$partition1)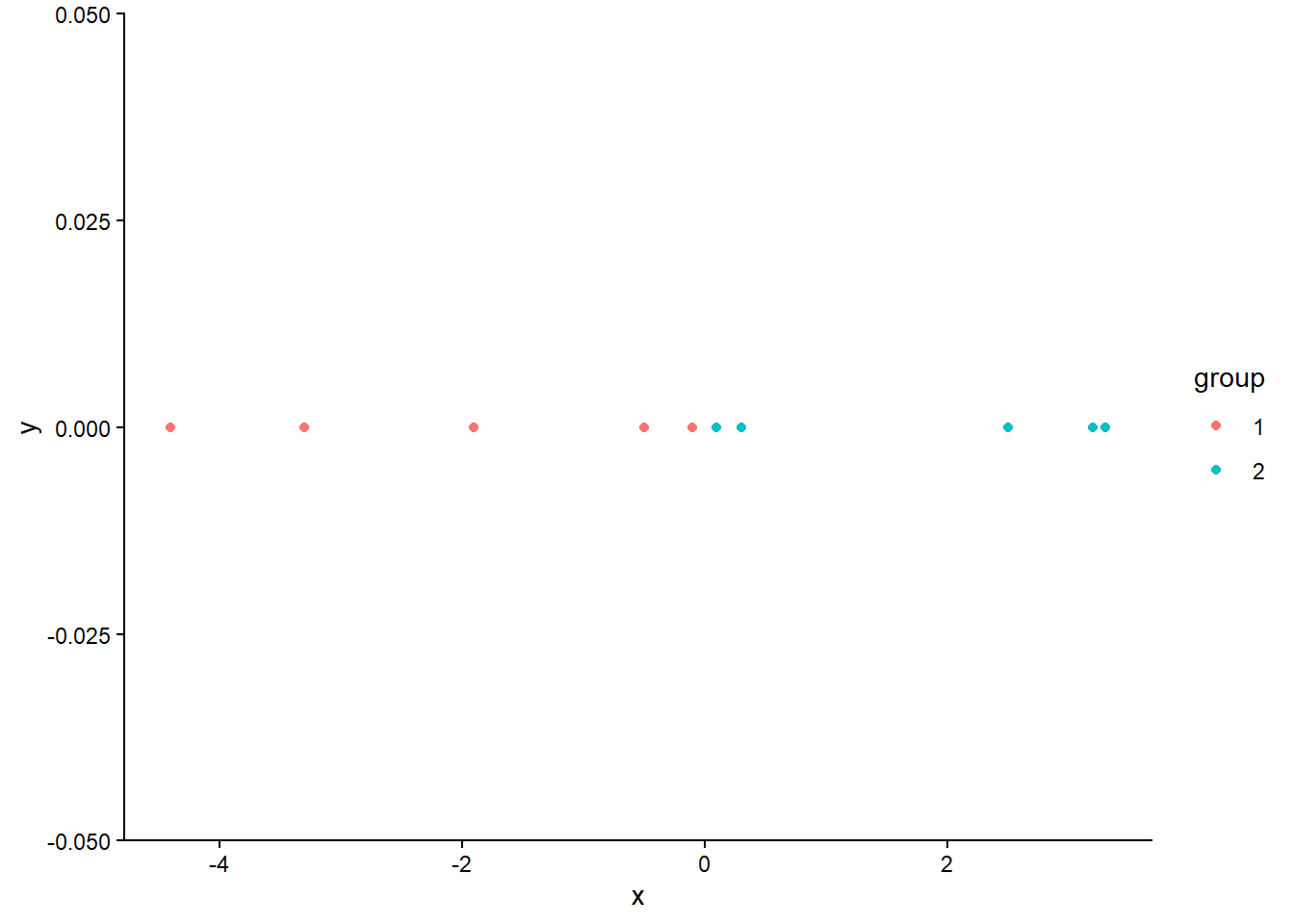
plot_data(data$Var, data$partition2)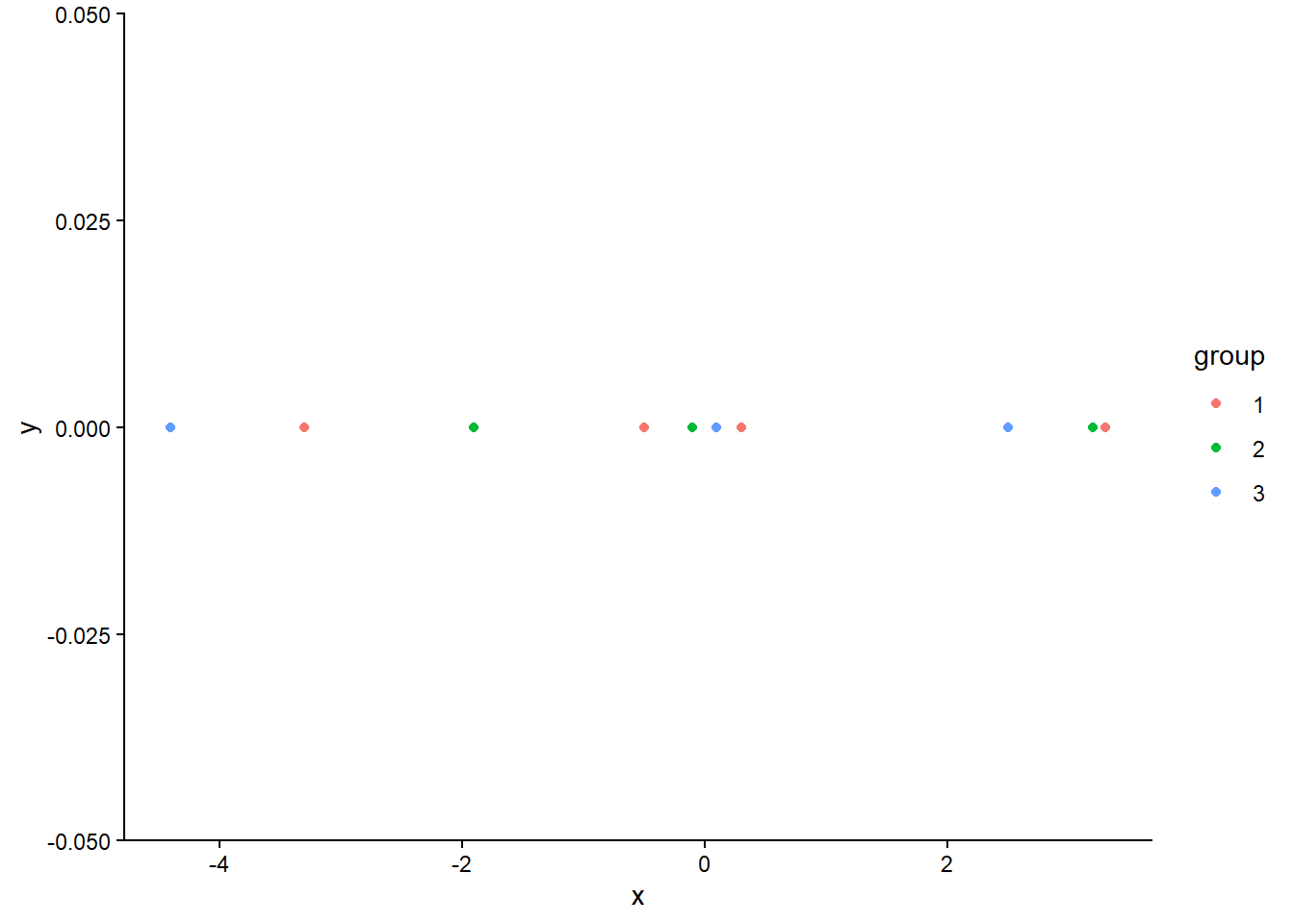
Initialisation de l’algorithme
Coder la fonction initEM(x, partition) qui retourne une liste imbriquée param contenant :
param$pi: l’init \(\pi^{(0)}\)param$thetaune sous-liste avecparam$theta$mu: l’init \(\mu^{(0)}\)param$theta$sigma2: l’init \({\sigma^2}^{(0)}\)
Tester votre fonction d’initialisation avec les partition1 et partition2 du jeu de données.
La fonction doit utiliser la partition initiale pour calculer les estimateurs des paramètres par maximum de vraisemblance dans chaque groupe.
initEM <- function(x, partition) {
K = n_distinct(partition)
param = list()
param$pi = table(partition) / length(partition)
param$theta = list()
param$theta$mu = rep(0, K)
param$theta$sigma2 = rep(0, K)
for (k in 1:K) {
param$theta$mu[k] = mean(x[partition == k])
nk = sum(partition == k)
param$theta$sigma2[k] = ((nk -1) / nk) * var(x[partition == k])
}
return(param)
}
param_0 = initEM(data$Var, data$partition1)
param_0$pi
partition
1 2
0.5 0.5
$theta
$theta$mu
[1] -2.04 1.88
$theta$sigma2
[1] 2.6624 1.9616initEM(data$Var, data$partition2)$pi
partition
1 2 3
0.4 0.3 0.3
$theta
$theta$mu
[1] -0.05 0.40 -0.60
$theta$sigma2
[1] 5.5275 4.4600 8.1800Etape E
Coder une fonction Estep(x, param) qui calcule et renvoie les \(\tau_{ik} = \frac{\pi_k \mathcal{N}(x_i, \mu_k, \sigma_k^2)}{\sum_l \pi_l \mathcal{N}(x_i, \mu_l, \sigma_l^2)}\).
Gardez à l’esprit que pour des valeurs de \(x_i\) très éloignées des \(\mu_k\), les quantités \(\pi_k \mathcal{N}(x_i, \mu_k, \sigma_k^2)\) peuvent devenir très petites et poser des problèmes numériques. Pour contourner ce problème, vous pouvez travailler dans le log-espace et calculer à la place :
\[\begin{equation*} \log \tau_{ik} = \log \pi_k + \log \mathcal{N}(x_i \mid \mu_k, \sigma^2_k) - cte_i \end{equation*}\]
où \(cte_i = {\log \sum_l \pi_l \mathcal{N}(x_i, \mu_l, \sigma_l^2)}\) est la constante de normalisation qui assure que \(\sum_k \tau_{ik} = 1\).
Cependant, il reste toujours le problème que, numériquement, \(\log e^{-1000} \approx \log 0 = - \infty\) tandis que mathématiquement \(\log(e^{-1000}) = - 1000\). Evidemment le \(-1000\) est arbitraire ici, mais dans la pratique, on peut facilement atteindre des valeurs aussi basses avec des données réelles. C’est ce que l’on appelle l’underflow, qui dépend de la précision du nombre flottant dans votre ordinateur (nombre de bits: 32, 64, 128 ?)
Mais il est possible de résoudre ce problème, ainsi la constante de normalisation peut-être calculée comme suit :
\[\begin{equation*} cte_i = m_i + \log \left( \sum_l \exp \left(\log \pi_l + \log \mathcal{N}(x_i \mid \mu_l, \sigma^2_l) - m_i \right) \right) \end{equation*}\]
où \(m_i = \max_l \left( \log \pi_l + \log \mathcal{N}(x_i \mid \mu_l, \sigma^2_l) \right)\). En effet, en soustrayant \(m_i\) dans l’exponentielle, on s’assure qu’il y a au moins un terme égal à \(\exp(0) = 1\) dans la somme, évitant ainsi les problèmes d’underflow.
Pour résumer, vous pouvez procéder comme suit :
- Calculer \(\log \tau_{ik}\) non-normalisés en utilisant les fonctions R existantes (comme
dnorm()). - Calculer la constante de normalisation \(cte_i\) de façon stable numériquement comme décrit précédemment.
- Normaliser les \(\log \tau_{ik}\) en soustrayant \(cte_i\).
- Exponentier pour obtenir \(\tau_{ik}\).
- Vérifier que les \(\tau_{ik}\) sont bien normalisées (somme à 1 par ligne).
logsumexp <- function(logx) {
# compute \log(\sum exp(logx)) by rescaling it by m = \max(logx)
# indeed : \log(\sum exp(logx)) = m + \log(\sum exp(logx - m))
# This ensures an exp(0) somewhere in the sum => avoid
# numerical underflows.
m = max(logx)
return(m + log(sum(exp(logx - m))))
}
Estep <- function(x, param) {
# Code in the log-space
n = length(x)
K = length(param$theta$mu)
logtau = matrix(0, n, K)
for (k in 1:K) {
logtau[,k] = log(param$pi[k]) +
dnorm(x=x, mean = param$theta$mu[k],
sd = sqrt(param$theta$sigma2[k]),
log = T) # use vectorization of dnorm()
}
# normalize in log-space with LogSumExp trick
logtau = logtau - apply(logtau, 1, logsumexp)
# Compute tau
tau = exp(logtau)
# sanity check that tau_i are normalized (sum to 1)
stopifnot(all.equal(rowSums(tau), rep(1, n)))
return(tau)
}
tau_0 = Estep(data$Var, param_0)
tau_0 [,1] [,2]
[1,] 0.998322097 0.0016779033
[2,] 0.999857197 0.0001428028
[3,] 0.970275611 0.0297243891
[4,] 0.006732798 0.9932672023
[5,] 0.019348146 0.9806518539
[6,] 0.007651619 0.9923483811
[7,] 0.367086378 0.6329136222
[8,] 0.448884498 0.5511155021
[9,] 0.534879918 0.4651200823
[10,] 0.699664342 0.3003356584Etape M
En utilisant les formules rappelées à Note 1, coder
- une fonction
compute_PI(tau)qui calcule \(\hat{\pi}\). - une fonction
compute_mu(tau, x)qui calcule \(\hat{\mu}_k\) pour tout \(k\). - une fonction
compute_sigma2(tau, mu, x)qui calcule \(\hat{\sigma}^2_k\) pour tout \(k\).
Les assembler dans une fonction Mstep(x, tau) qui constitue la M-step de l’algorithme EM.
Vous pouvez utiliser des boucles for pour parcourir les clusters et les observations, ou utiliser des fonctions vectorisées de R pour optimiser les calculs.
compute_PI = function(tau) {
n = dim(tau)[1]
return(colSums(tau) / n)
}
compute_PI(tau_0)[1] 0.5052703 0.4947297compute_mu = function(tau, x) {
N = nrow(tau)
K = ncol(tau)
mu = rep(0, K)
for(k in 1:K) {
norm = 0
for (i in 1:N) {
norm = norm + tau[i, k]
mu[k] = mu[k] + tau[i,k] * x[i]
}
mu[k] = mu[k] / norm
}
return(mu)
}
mu_1 = compute_mu(tau=tau_0, x=data$Var)
mu_1[1] -1.917902 1.797060compute_sigma2 = function(tau, x, mu) {
N = nrow(tau)
K = ncol(tau)
sigma2 = rep(0, K)
for(k in 1:K) {
norm = 0
for (i in 1:N) {
norm = norm + tau[i,k]
sigma2[k] = sigma2[k] + tau[i,k] * (x[i] - mu[k])^2
}
sigma2[k] = sigma2[k] / norm
}
return(sigma2)
}
compute_sigma2(tau = tau_0, x=data$Var, mu = mu_1)[1] 3.094669 2.304496Mstep = function(x, tau) {
# list for storing the result
param = list()
param$theta = list()
# compute pi_hat
param$pi = compute_PI(tau)
# compute mu_hat
param$theta$mu = compute_mu(tau, x)
# compute sigma² hat
param$theta$sigma2 = compute_sigma2(tau, x, mu = param$theta$mu)
return(param)
}
param_1 = Mstep(x=data$Var, tau = tau_0)
param_1$theta
$theta$mu
[1] -1.917902 1.797060
$theta$sigma2
[1] 3.094669 2.304496
$pi
[1] 0.5052703 0.4947297Calcul de la vraisemblance marginale
Coder une fonction compute_mixture_llhood = function(x, param) qui retourne la log-vraisemblance marginale des observations : \[\begin{equation*}
\log p (x_1, \ldots, x_n \mid \theta, \pi) = \sum_i \log \sum_k \pi_k \mathcal{N}(x_i \mid \mu_k, \sigma^2_k)
\end{equation*}\]
Utiliser la vectorisation de dnorm() pour éviter une boucle sur les observations.
compute_mixture_llhood = function(x, param) {
N = length(x)
K = length(param$theta$mu)
# /!\ This method sould not be used (too slow)
# ---------- Brute force double loop
# llhood = 0
# for(i in 1:N) {
# temp = 0
# for(k in 1:K) {
# temp = temp +
# param$pi[k] * dnorm(x=x[i],
# mean = param$theta$mu[k],
# sd = sqrt(param$theta$sigma2[k]),
# log = F)
# }
# llhood = llhood + log(temp)
# }
# ------------ use vectorization of dnorm
lhoods = matrix(0, N, K)
for(k in 1:K) {
lhoods[,k] = param$pi[k] *
dnorm(x=x, mean = param$theta$mu[k],
sd = sqrt(param$theta$sigma2[k]),
log = F)
}
lhoods = sum(log(rowSums(lhoods)))
return(sum(lhoods))
}
cat("Llhood à l\'init : ", compute_mixture_llhood(data$Var, param_0) , '\n')Llhood à l'init : -23.15126 Algorithme EM complet
Mettre toute ces fonctions ensemble dans une fonction EMgauss1D(X, K, partition_init, max.iter, rtol). L’algorithme s’arrête après un nombre fixé max.iter d’itérations ou quand la différence relative entre les vraisemblances successive à \(t\) et \(t+1\) est inférieur au seuil rtol : \[\begin{equation*}
\vert \frac{\log p_{\theta^{(t+1)}}(X) - \log p_{\theta^{(t)}}(X)}{\log p_{\theta^{(t)}}(X)} \vert < rtol.
\end{equation*}\]
La fonction devra retourner une liste avec les élémets suivants :
logliks: la valeur successive des vraisemblance le long des itération (pour l’afficher dans un graphique par exemple),param: les paramètres à la fin de l’algorithme,tau: les probabilité a posteriori d’appartenir à chacuns des groupes.
Attention, elles doivent être calculées avec les valeurs des paramètres finales.
Tester votre fonction avec les hyper-paramètres suivants:
max.iter = 20
rtol = 1e-6
K = 2
partition_init = data$partition1Vous pouvez vous inspirer de la structure suivante pour votre fonction EM :
- Initialisation des paramètres avec
initEM() - Boucle principale de l’algorithme EM :
- E-step avec
Estep() - M-step avec
Mstep() - Calcul de la log-vraisemblance marginale avec
compute_mixture_llhood() - Test de convergence de la log-vraisemblance marginale
- Stockage et affichage de la log-vraisemblance à chaque itération
- E-step avec
- Calcul final des \(\tau\) avec les paramètres finaux
- Retourner les résultats dans une liste
EMgauss1D <- function(x, K, partition_init, max.iter, rtol) {
# sanity check
if (length(unique(partition_init)) != K) {
stop('The init partition must have the same number of clusters as K')
}
# initialization
param = initEM(x=x, partition=partition_init)
logliks = rep(NA, max.iter+1) # store de loglikelihoods values
logliks[1] = compute_mixture_llhood(x, param)
cat("Llhood à l\'init ", logliks[1], '\n')
for(ite in 1:max.iter) {
old = compute_mixture_llhood(x, param)
# E-step (use current param)
tau = Estep(x=x, param=param)
# M-step (update param)
param = Mstep(x = x, tau = tau)
# test convergence
new = compute_mixture_llhood(x = x, param = param)
logliks[ite+1] = new
criterion = abs((new - old)/old)
if(criterion < rtol) break;
#sanity check that the likelihoods do not decrease
stopifnot(new >= old)
# affichage à chaque itération
cat("Llhood à l\'étape ", ite, " : ", new, '\n')
}
# compute tau one last time with the value of the final parameters
tau = Estep(x, param)
return(list(logliks=logliks, tau=tau, param=param))
}
res_em = EMgauss1D(x=data$Var, K=K, partition_init = partition_init,
max.iter = max.iter , rtol = rtol) Llhood à l'init -23.15126
Llhood à l'étape 1 : -23.03423
Llhood à l'étape 2 : -23.01722
Llhood à l'étape 3 : -23.01268
Llhood à l'étape 4 : -23.01117
Llhood à l'étape 5 : -23.0106
Llhood à l'étape 6 : -23.01035
Llhood à l'étape 7 : -23.01022
Llhood à l'étape 8 : -23.01014
Llhood à l'étape 9 : -23.01008
Llhood à l'étape 10 : -23.01002
Llhood à l'étape 11 : -23.00996
Llhood à l'étape 12 : -23.00989
Llhood à l'étape 13 : -23.00983
Llhood à l'étape 14 : -23.00976
Llhood à l'étape 15 : -23.00969
Llhood à l'étape 16 : -23.00961
Llhood à l'étape 17 : -23.00952
Llhood à l'étape 18 : -23.00943
Llhood à l'étape 19 : -23.00934
Llhood à l'étape 20 : -23.00924 plot(0:max.iter, res_em$logliks)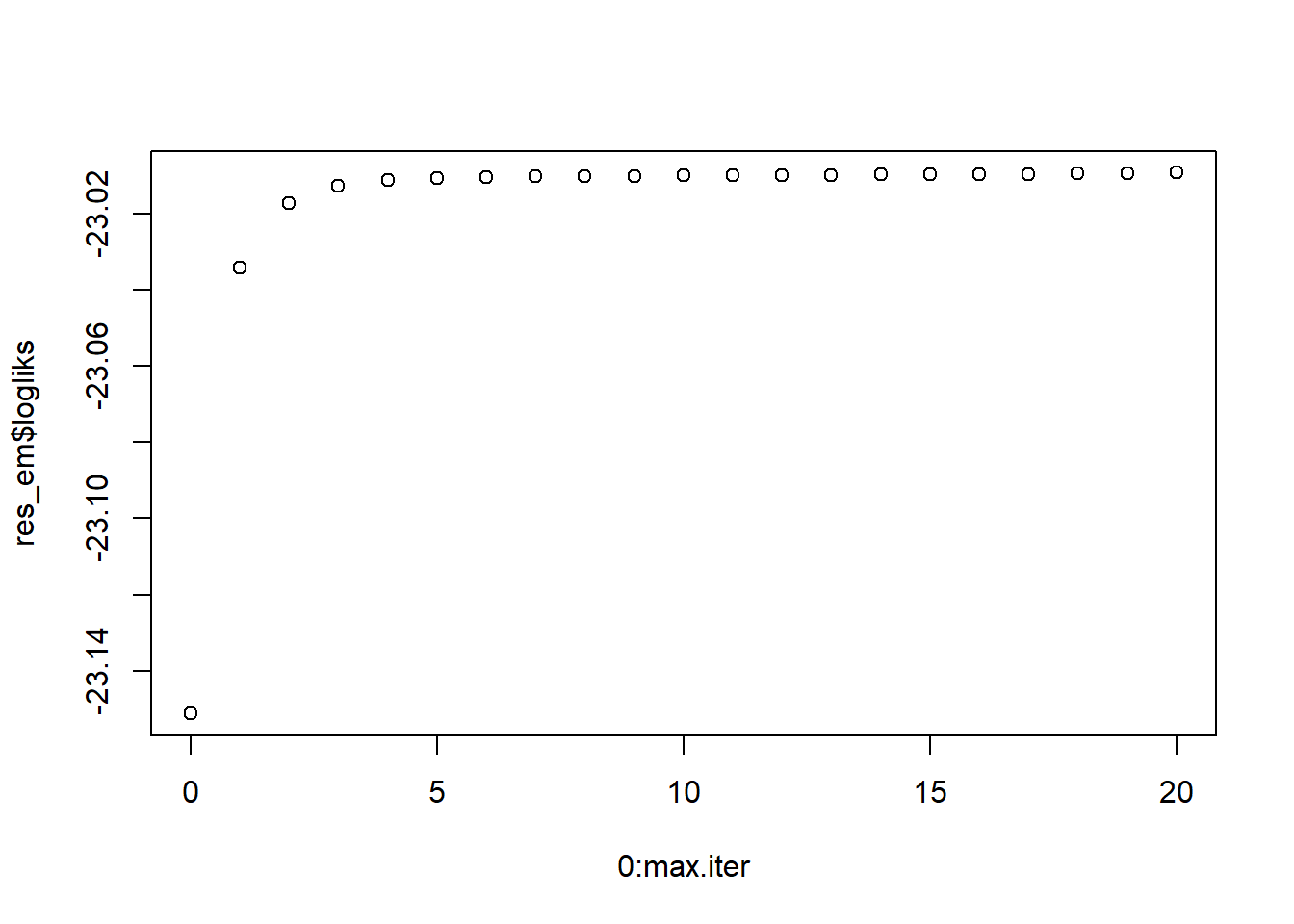
Note On peut jouer avec le paramètre
max.iteretrtolpour la convergence de la vraisemblance. Ne pas oublier que l’on converge uniquement vers un maximum local de cette dernière. On peut ensuite visualiser les estimateur des paramètre \((\hat{\pi_k}, \hat{\mu_k}, \hat{\Sigma_k})_k\)
Visualisation des résultats
Afficher les données initiales, coloriée par rapport à leur probabilité d’appartenance au Cluster 1. Ajouter les densités des composantes gaussiennes estimées pour chaque cluster à la fin de l’algorithme EM.
Vous pouvez utiliser la fonction stat_function() de ggplot2 pour ajouter des courbes représentant les densités des composantes gaussiennes. N’oubliez pas de multiplier chaque densité par le poids \(\hat{\pi}_k\) correspondant.
data_clust = data %>%
mutate(prob_cluster1 = res_em$tau[,1])
ggplot(data_clust) +
geom_point(aes(x=Var, y=-0.01, color = prob_cluster1)) +
scale_color_gradientn(colours = c('blue', 'purple', 'red')) +
stat_function(fun = function(x) {
res_em$param$pi[1] * dnorm(x, mean = res_em$param$theta$mu[1], sd = sqrt(res_em$param$theta$sigma2[1]))
}, color = 'red') +
stat_function(fun = function(x) {
res_em$param$pi[2] * dnorm(x, mean = res_em$param$theta$mu[2], sd = sqrt(res_em$param$theta$sigma2[2]))
}, color = 'blue') +
xlim(-8, 8) +
theme_classic()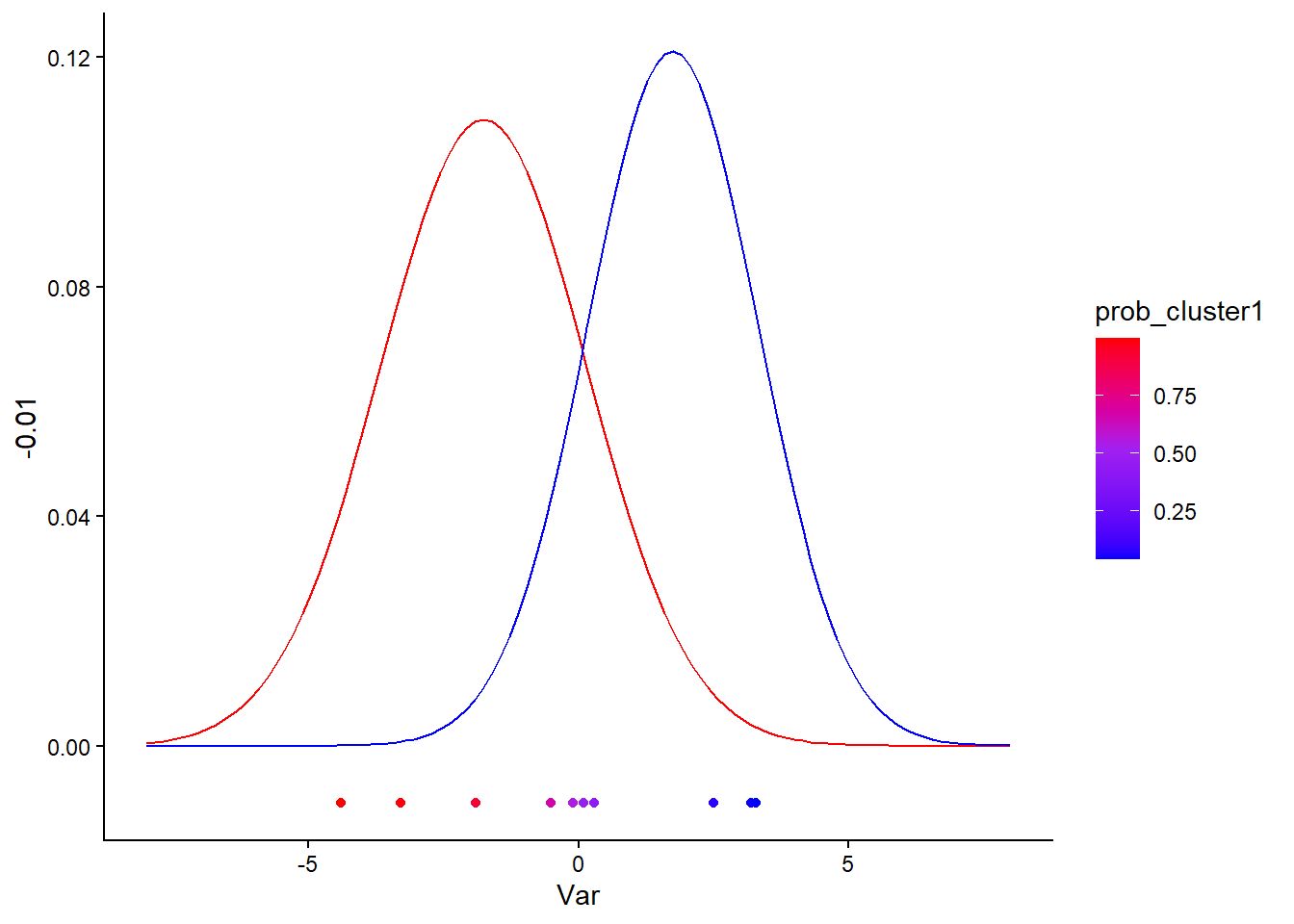
Utilisation avec 3 clusters
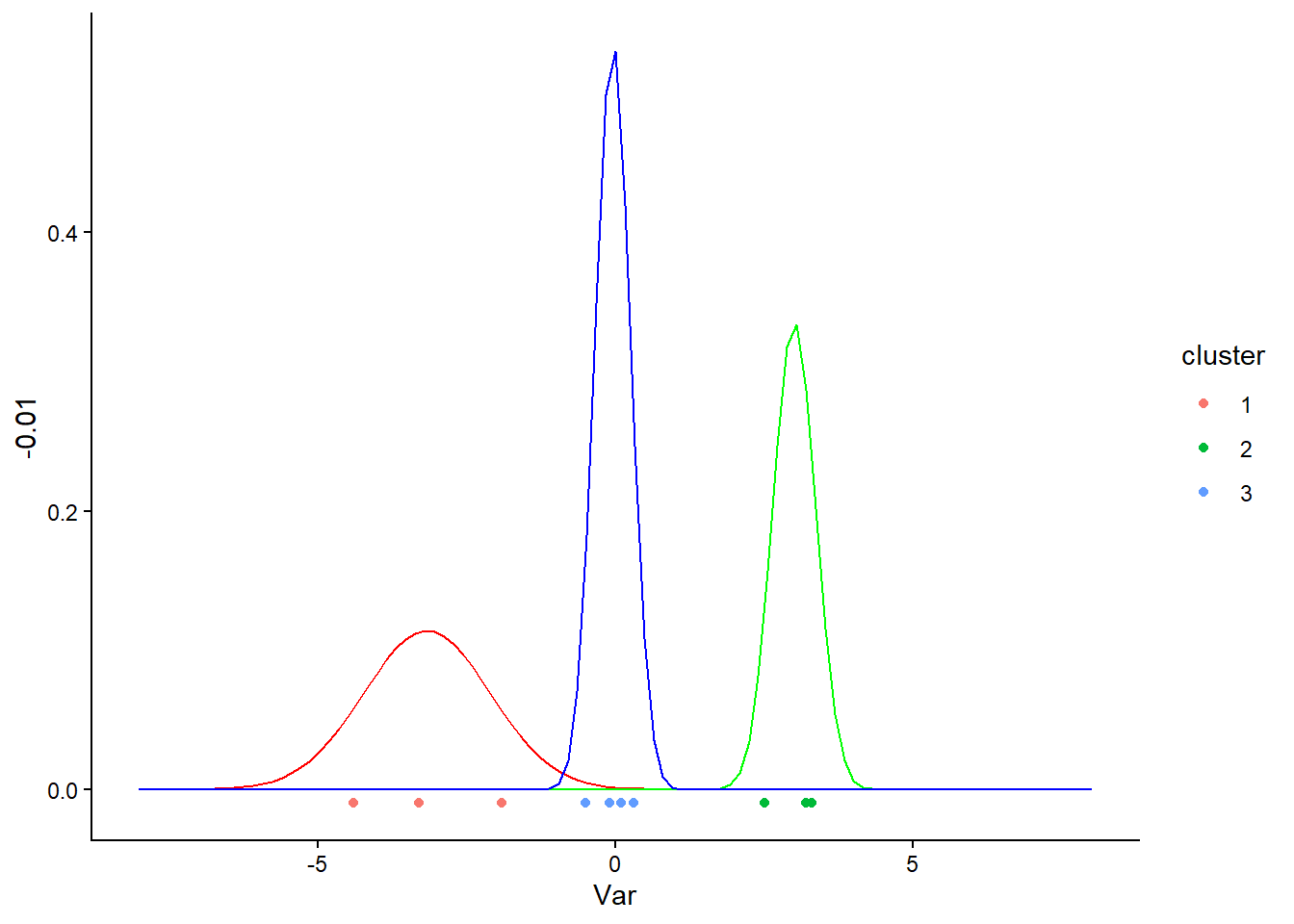
Tester votre algorithme EM avec K=3 clusters en initialisant la partition avec un kmeans préalable. Afficher les résultats finaux comme précédemment.
Vous pouvez utiliser la fonction kmeans() de R pour obtenir une partition initiale avec 3 clusters. Pour visualiser les résultats avec 3 clusters, vous pouvez calculer la probabilité d’appartenance maximale pour chaque point et colorier les points en conséquence.
set.seed(42)
K = 3
km3 = kmeans(data$Var, centers = K, nstart = 20)
res_em_3 = EMgauss1D(x=data$Var, K=K, partition_init = km3$cluster,
max.iter = max.iter , rtol = rtol)Llhood à l'init -17.14946
Llhood à l'étape 1 : -17.14516
Llhood à l'étape 2 : -17.14482
Llhood à l'étape 3 : -17.14478 ## Find the most probable cluster for each point
data_clust_3 = data %>%
mutate(cluster = apply(res_em_3$tau, 1, which.max) %>% as.factor())
ggplot(data_clust_3) +
geom_point(aes(x=Var, y=-0.01, color = cluster)) +
stat_function(fun = function(x) {
res_em_3$param$pi[1] * dnorm(x, mean = res_em_3$param$theta$mu[1], sd = sqrt(res_em_3$param$theta$sigma2[1]))
}, color = 'red') +
stat_function(fun = function(x) {
res_em_3$param$pi[2] * dnorm(x, mean = res_em_3$param$theta$mu[2], sd = sqrt(res_em_3$param$theta$sigma2[2]))
}, color = 'green') +
stat_function(fun = function(x) {
res_em_3$param$pi[3] * dnorm(x, mean = res_em_3$param$theta$mu[3], sd = sqrt(res_em_3$param$theta$sigma2[3]))
}, color = 'blue') +
xlim(-8, 8) +
theme_classic()