library(tidyverse)TP Statistiques Bayésiennes: loi conjuguées
Lois a posteriori pour le modèles beta-binomial
On rappelle le modèle : 1. \(p \sim \mathcal{B}e(\alpha, \beta)\) 2. \(x \mid \pi \sim \mathcal{B}(N, p)\)
On souhaite calculer et visualiser la loi a posteriori du paramètre de proportion \(p\) sachant \(x\). Ce modèle peut classiquement s’interpréter comme le modèle d’observation de \(N\) pièces de monnaie identiques, où \(p\) est la probabilité d’obtenir face.
D’après le théorème de Bayes, on sait que : \[ p \mid x \sim \mathcal{B}e(\alpha + x, \beta + N - x) \tag{1}\]
On fixe les valeurs de paramètres suivantes, mais votre code doit pouvoir se généraliser facilement.
N = 10
alpha = 2
beta = 2Exercice 1
Coder une fonction simu_binom(N, p) qui simule un modèle binomial avec paramètre \(N\) et \(p\).
Consulter l’aide ?rbinom
simu_binom = function(N, p) {
x = rbinom(n=1, size = N, prob = p)
return(x)
}Exercice 2
Soit la simulation suivante:
set.seed(123)
simu = simu_binom(N=10, p=0.7)
simu[1] 8Coder la loi a posteriori de \(p \mid x\) et tracer la densité de cette loi a posteriori. Tracer sur le même graphique la loi a priori pour comparaison.
Voir le rappel de la loi a posteriori : Equation 1. Vous pouvez utiliser la fonction dbeta pour calculer la densité de la loi bêta.
x = simu
posterior_alpha = alpha + x
posterior_beta = beta + N - x
p_seq = seq(0, 1, length.out = 100)
posterior_density = dbeta(p_seq, shape1 = posterior_alpha, shape2 = posterior_beta)
prior_density = dbeta(p_seq, shape1 = alpha, shape2 = beta)
df = tibble(p = p_seq, density = posterior_density, type = "Posterior") %>%
bind_rows(tibble(p = p_seq, density = prior_density, type = "Prior"))
ggplot(df) +
geom_line(aes(x = p, y = density, col = type, linetype = type)) +
ggtitle(paste("Loi a priori/posteriori de p avec x =", x)) +
xlab("p") +
ylab("Densité") +
theme_classic()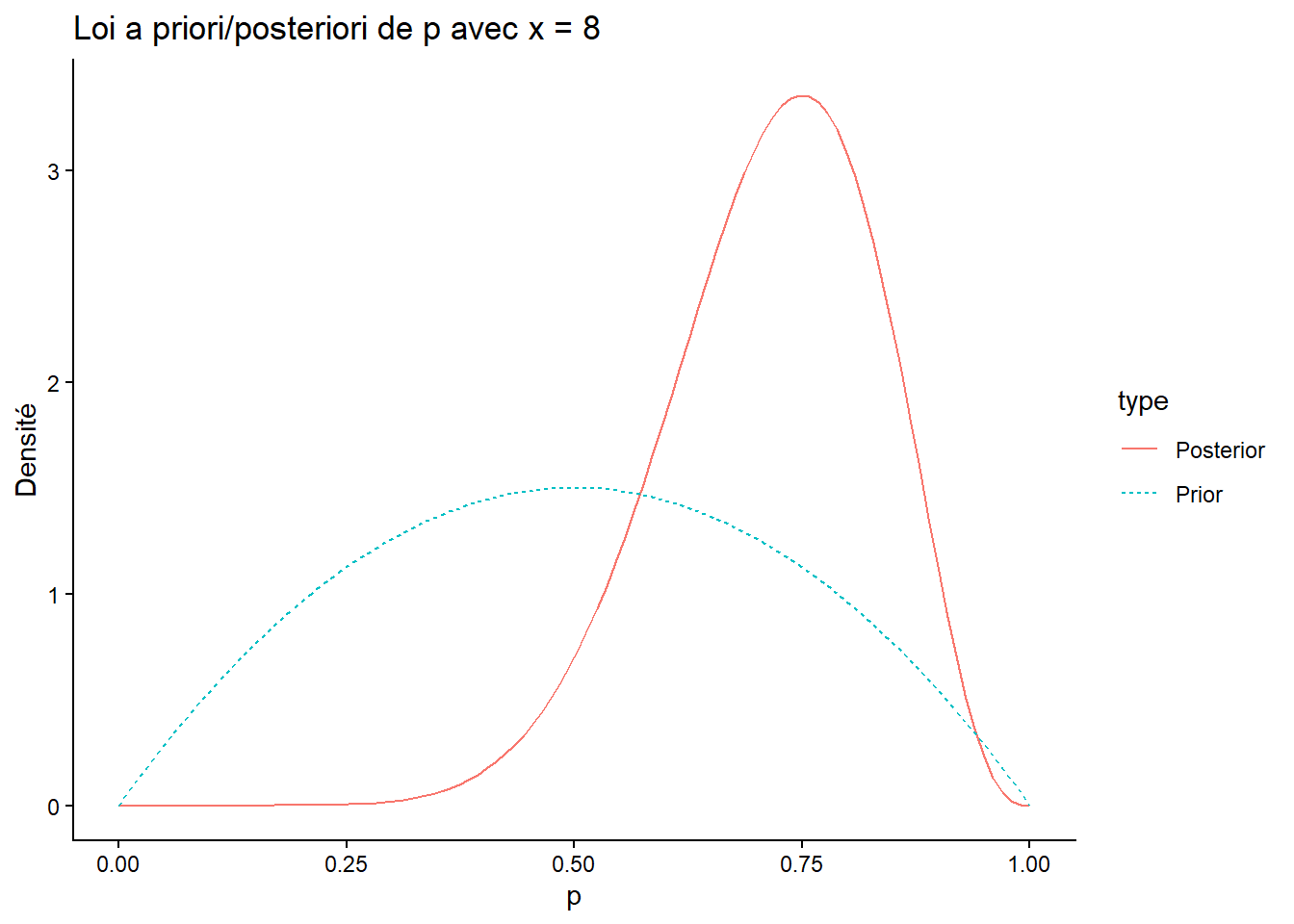
Exercice 3
Répéter l’expérience de l’exercice 2 pour différentes valeurs de \(x\) dans \(\{0, 1, \ldots, N\}\) et tracer les différentes densités sur le même graphique.
Vous pouvez utiliser une boucle pour calculer les densités pour chaque valeur de \(x\) et stocker les résultats dans un data frame. Ensuite, utilisez ggplot2 pour tracer toutes les densités sur le même graphique en utilisant geom_line().
df_all = tibble()
for (x in 0:N) {
posterior_alpha = alpha + x
posterior_beta = beta + N - x
posterior_density = dbeta(p_seq, shape1 = posterior_alpha, shape2 = posterior_beta)
df_temp = tibble(p = p_seq, density = posterior_density, x = as.factor(x))
df_all = bind_rows(df_all, df_temp)
}
ggplot(df_all) +
geom_line(aes(x = p, y = density, color = x)) +
ggtitle("Lois a posteriori p | x pour différentes valeurs de x") +
xlab("p") +
ylab("Densité") +
labs(color = "x") +
theme_classic()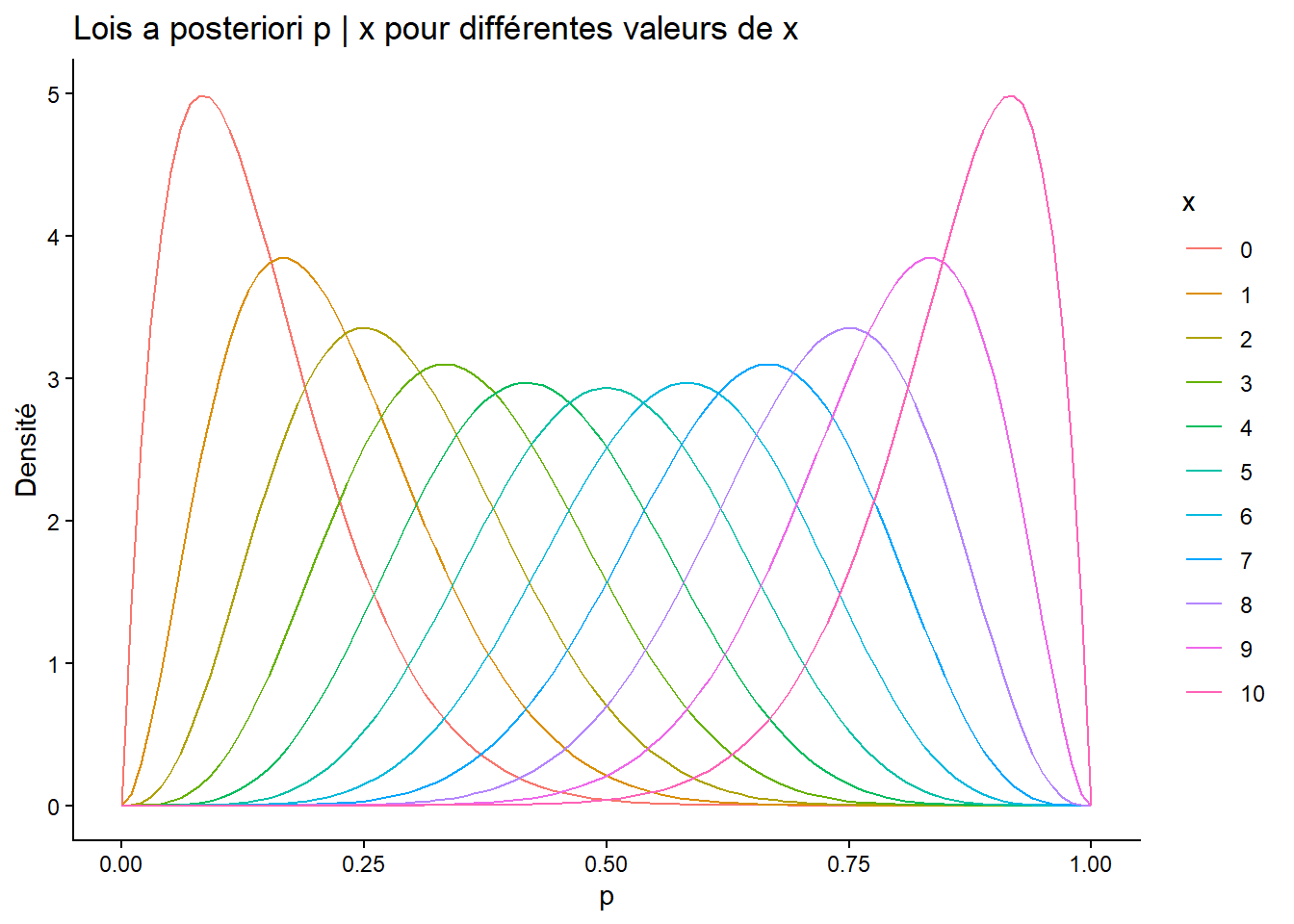
Estimateurs pour le modèle Dirichlet-Multinomial
On rappelle le modèle :
- \(\pi \sim \mathcal{D}_K(\alpha_1, \ldots, \alpha_K)\)
- \(x \mid \pi \sim \mathcal{M}_K(N, \pi)\)
On souhaite comparer empiriquement les estimateurs du maximum de vraisemblance et de Bayes pour la perte \(L_2\).
\[ \begin{align*} \hat{\pi}_{k}^{MLE} &= \frac{x_k}{N}, \\ \hat{\pi}_{k}^{Bayes} &= \frac{ \alpha_k + x_k}{\sum_l \alpha_l + x_l} \end{align*} \tag{2}\]
On fixe \(K=4\) et les valeurs de paramètres suivantes, mais votre code doit pouvoir se généraliser facilement.
K = 4
alpha = c(1,1,1,1)
PI = c(0.1, 0.2, 0.65, 0.05)
stopifnot(sum(PI) == 1) # sanity checkExercice 4
Coder une fonction simu_multi(N, PI) qui simule un modèle multinomial avec paramètre \(N\) et \(\pi\).
Consulter l’aide ?rmultinom
library(stats)
simu_multi = function(N, PI) {
x = rmultinom(n=1, size = N, prob = PI)
return(x)
}Exercice 5
Soit la simulation suivante:
simu = simu_multi(N=100, PI=PI)
simu [,1]
[1,] 12
[2,] 19
[3,] 61
[4,] 8Coder les 2 estimateurs \(\hat{\pi}_{ML}\) et \(\hat{\pi}_{Bayes}\) en R puis calculer leur différence absolue (norme L1 de la différence) \(\Vert \hat{\pi}_{ML}-\hat{\pi}_{Bayes}\Vert_1\)
Voir le rappel des formules des estimateurs : Equation 2
PI_ML = simu / sum(simu)
PI_Bayes = (simu + alpha) / sum(simu + alpha)
sum(abs(PI_ML - PI_Bayes))[1] 0.02769231Exercice 6
Coder une fonction simu_multi(N, PI) qui simule un modèle multinomial avec paramètre \(N\) et \(\pi\).
On souhaite faire un nombre grand d’expériences (disons 100) pour des valeurs de \(N\) qui varient, afin de mieux comprendre la différence et la similarité entre les 2 estimateurs au fur et à mesure que le nombre d’observations augmente.
n_exp = 100
Ns = c(seq(10,1000, 10), 1e4)Pour chaque valeurs de N dans le vecteur Ns, répéter n_exp expériences de simulation selon le modèle multinomiale avec \(N\) et \(\pi^\star\). Calculer la valeur moyenne des trois erreurs suivantes
- Erreur relative: \(\Vert \hat{\pi}_{ML}-\hat{\pi}_{Bayes}\Vert_1\)
- Erreur de l’estimateur frequentiste : \(\Vert \hat{\pi}_{ML}- \pi^\star \Vert_1\)
- Erreur de l’estimateur Bayésien : \(\Vert \hat{\pi}_{Bayes}- \pi^\star \Vert_1\)
Vous pouvez boucler sur les valeurs de N, puis pour chaque valeur de N, boucler sur le nombre d’expériences. Stocker les résultats dans des matrices où chaque ligne correspond à une expérience et chaque colonne à une valeur de N. Enfin, faire la moyenne par colonne pour obtenir la moyenne des erreurs pour chaque valeur de N.
n_exp = 100
Ns = c(seq(10,1000, 10), 1e4)
l1_relat = matrix(0, n_exp, length(Ns))
l1_ML = matrix(0, n_exp, length(Ns))
l1_Bayes = matrix(0, n_exp, length(Ns))
for (j in 1:length(Ns)) {
N = Ns[j]
for (i in 1:n_exp) {
simu = simu_multi(N=N, PI=PI)
PI_ML = simu / sum(simu)
PI_Bayes = (simu + alpha) / sum(simu + alpha)
l1_relat[i, j] = sum(abs(PI_ML - PI_Bayes))
l1_ML[i, j] = sum(abs(PI_ML - PI))
l1_Bayes[i, j] = sum(abs(PI_Bayes - PI))
}
}
relat_avg = colMeans(l1_relat) # average each column to get average for the 100 expes
ML_avg = colMeans(l1_ML)
Bayes_avg = colMeans(l1_Bayes)Exercice 7
Tracer 2 graphiques avec ggplot2 :
l’évolution de l’erreur relative entre les 2 estimateurs en fonction de \(N\).
l’évolution en fonction \(N\) de l’erreur d’estimation du vrai paramètre \(\pi^\star\), pour les deux estimateurs sur le même graphique.
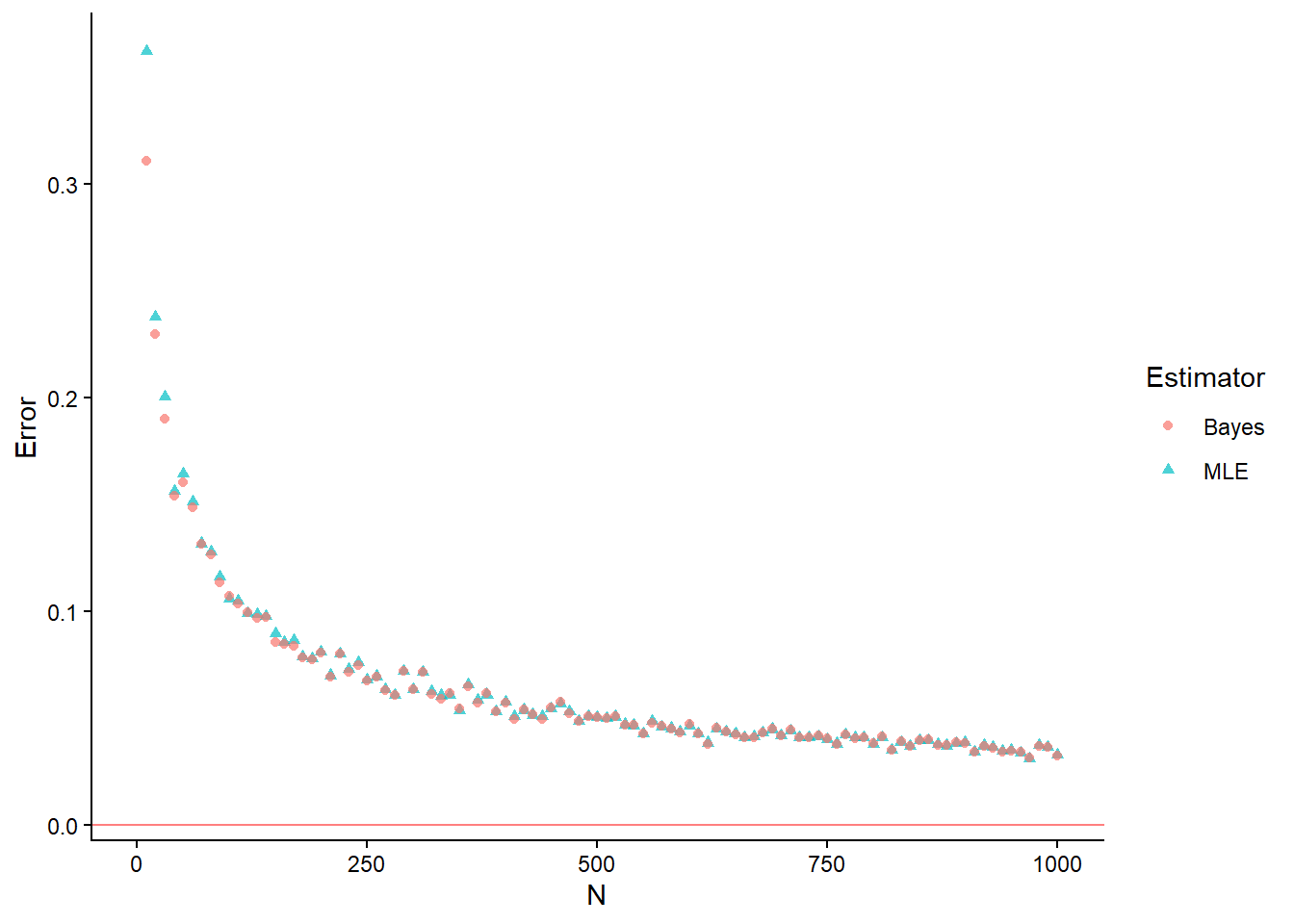
Que constatez-vous ? Est-ce attendu ?
Vous pouvez utiliser geom_line() pour tracer les courbes. Pour le second graphique, vous pouvez utiliser pivot_longer() pour transformer les données en format long, ce qui facilite la création de graphiques avec plusieurs séries (en les distinguant par exemple par couleur via l’argument color dans les aesthetics aes()).
df = tibble(N = Ns, Error = relat_avg)
ggplot(df) +
geom_line(aes(x = N, y = Error)) +
geom_abline(col="red", slope = 0, intercept = 0) + # visual indicator
ggtitle("Erreur L1 relative entre les 2 estimateurs") +
theme_classic() 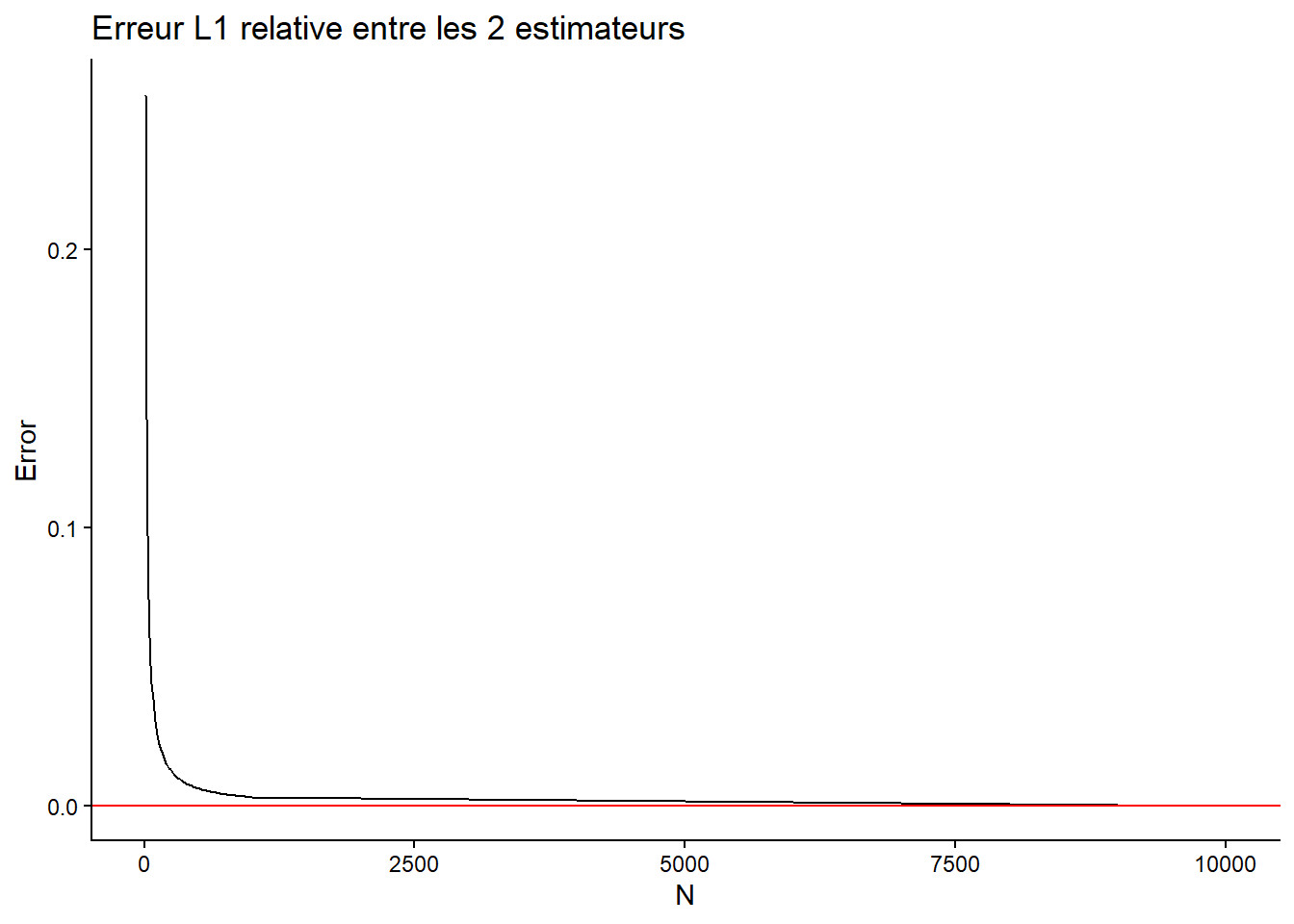
df2 = tibble(N = Ns, MLE = ML_avg, Bayes = Bayes_avg) |>
pivot_longer(cols = c("MLE", "Bayes"), names_to = "Estimator", values_to = "Error")
ggplot(df2) +
geom_point(aes(x = N, y = Error, col = Estimator, shape = Estimator), alpha = 0.7)+
geom_abline(intercept = 0, slope=0, col="red", alpha=0.5) +
xlim(0, 1000) +
theme_classic()