Examen – Algorithme EM pour un modèle de processus gaussiens multitâches
M2 Data Science – Statistique bayésienne et variables latentes
Durée : 1h
Documents autorisés : aucun, devoir sur feuille
Objectif : Dériver les calculs nécessaires à la définition d’un algorithme EM permettant d’entraîner un modèle GP multitâches.
1. Modèle et données
On considère le modèle suivant, pour \(i = 1, \dots, T\) :
\[ y_i(x) = \mu_0(x) + f_i(x) + \varepsilon_i \]
avec :
- \(\mu_0 \sim \mathcal{GP}(m_0, k_0)\) : processus moyen latent,
- \(f_i \sim \mathcal{GP}(0, k_{\theta_i})\) : processus spécifique à la tâche \(i\),
- \(\varepsilon_i \sim \mathcal{N}(0, \sigma_i^2 I)\),
- tous les processus sont indépendants a priori.
On observe \(T\) tâches définies sur une même grille \(x = (x_1, \dots, x_n)\).
Le modèle graphique génératif est le suivant :
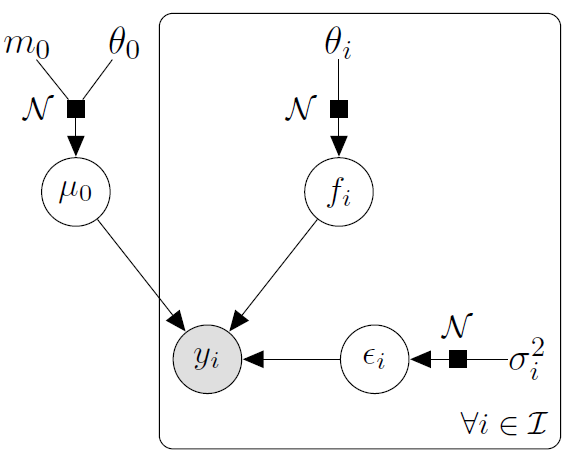
L’objectif est d’estimer les paramètres \(\theta = (\{\theta_i, \sigma_i^2\}_{i=1}^T)\), ainsi que la loi a posteriori du processus latent \(\mu_0\), à partir des observations \(y = \{y_i\}_{i=1}^T\).
Pour cela, il est possible d’utiliser un algorithme EM en considérant \(\mu_0\) comme une variable latente. On note \(Y = (y_1, \dots, y_T)\) la matrice des observations de taille \(n \times T\) et \(m_0 = (m_0(x_1), \dots, m_0(x_n))^T\) le vecteur des moyennes du processus moyen latent sur la grille d’observation.
La loi a posteriori de \(\mu_0\) conditionnellement aux observations et aux paramètres courants \(\theta^{(k)}\) s’écrit : \[ p(\mu_0 | Y, \theta^{(k)}) = \mathcal{N}(\hat{\mu}^{(k)}, \hat{\Sigma}^{(k)}) \] avec :
\[ \begin{aligned} \hat{\Sigma}^{(k)} &= \left( K_0^{-1} + \sum_{i=1}^T (K_{\theta_i^{(k)}} + \sigma_i^{2(k)} I)^{-1} \right)^{-1} \\ \hat{\mu}^{(k)} &= \hat{\Sigma}^{(k)} \left( K_0^{-1} m_0 + \sum_{i=1}^T (K_{\theta_i^{(k)}} + \sigma_i^{2(k)} I)^{-1} y_i \right) \end{aligned} \]
Calculer ces paramètres de moyenne et variance a posteriori correspond à l’étape E de l’algorithme EM.
Nous pouvons grâce à cette loi a posteriori calculer l’espérance de la log-vraisemblance complète :
\[\begin{aligned} Q(\theta | \theta^{(k)}) &= \mathbb{E}_{\mu_0 | Y, \theta^{(k)}} [\log p(Y, \mu_0 | \theta)] \\ &= \sum\limits_{i=1}^T \log \ \mathcal{N}(y_i; \hat{\mu}^{(k)}, K_{\theta_i} + \sigma_i^2 I) + tr \left( (K_{\theta_i} + \sigma_i^2 I)^{-1} \hat{\Sigma}^{(k)} \right) \\ \end{aligned}\]L’étape M consiste à maximiser cette espérance par rapport aux paramètres \(\theta\) pour obtenir les nouveaux paramètres \(\theta^{(k+1)}\).
Consigne :
Ecrivez la preuve des formules données ci-dessus pour les étapes E et M de l’algorithme EM dans ce contexte. Plus concrétement, détaillez le calcul de la loi a posteriori de \(p(\mu_0 | Y, \theta^{(k)})\) jusqu’à arriver aux expressions de \(\hat{\mu}^{(k)}\) et \(\hat{\Sigma}^{(k)}\). Décrivez également les étapes intermédiaires du calcul de l’espérance conditionnelle \(\mathbb{E}_{\mu_0 | Y, \theta^{(k)}} [\log p(Y, \mu_0 | \theta)]\) permettant d’obtenir la formule finale ci-dessus.
Vous pouvez vous appuyer sur les propriétés des distributions gaussiennes et des espérances conditionnelles pour mener à bien cette dérivation.