set.seed(42)
kern_se <- function(X, l, v) {
# Insert your code here
}Examen – Algorithme EM pour un modèle de processus gaussiens multitâches
M2 Data Science – Statistique bayésienne et variables latentes
Durée : 1h
Documents autorisés : aucun, pas d’accès internet
Objectif : implémenter un algorithme EM permettant d’entraîner un modèle GP multitâches.
1. Modèle et données
On considère le modèle suivant, pour \(i = 1, \dots, T\) :
\[ y_i(x) = \mu_0(x) + f_i(x) + \varepsilon_i \]
avec :
- \(\mu_0 \sim \mathcal{GP}(m_0, k_0)\) : processus moyen latent,
- \(f_i \sim \mathcal{GP}(0, k_{\theta_i})\) : processus spécifique à la tâche \(i\),
- \(\varepsilon_i \sim \mathcal{N}(0, \sigma_i^2 I)\),
- tous les processus sont indépendants a priori.
On observe \(T\) tâches définies sur une même grille \(x = (x_1, \dots, x_n)\).
Le modèle graphique génératif est le suivant :
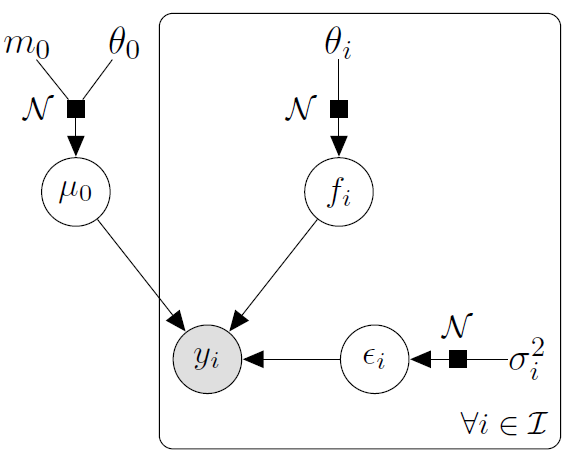
L’objectif est d’estimer les paramètres \(\theta = (\{\theta_i, \sigma_i^2\}_{i=1}^T)\), ainsi que la loi a posteriori du processus latent \(\mu_0\), à partir des observations \(y = \{y_i\}_{i=1}^T\).
Pour cela, il est possible d’utiliser un algorithme EM en considérant \(\mu_0\) comme une variable latente. On note \(Y = (y_1, \dots, y_T)\) la matrice des observations de taille \(n \times T\) et \(m_0 = (m_0(x_1), \dots, m_0(x_n))^T\) le vecteur des moyennes du processus moyen latent sur la grille d’observation.
La loi a posteriori de \(\mu_0\) conditionnellement aux observations et aux paramètres courants \(\theta^{(k)}\) s’écrit : \[ p(\mu_0 | Y, \theta^{(k)}) = \mathcal{N}(\hat{\mu}^{(k)}, \hat{\Sigma}^{(k)}) \] avec :
\[ \begin{aligned} \hat{\Sigma}^{(k)} &= \left( K_0^{-1} + \sum_{i=1}^T (K_{\theta_i^{(k)}} + \sigma_i^{2(k)} I)^{-1} \right)^{-1} \\ \hat{\mu}^{(k)} &= \hat{\Sigma}^{(k)} \left( K_0^{-1} m_0 + \sum_{i=1}^T (K_{\theta_i^{(k)}} + \sigma_i^{2(k)} I)^{-1} y_i \right) \end{aligned} \]
Calculer ces paramètres de moyenne et variance a posteriori correspond à l’étape E de l’algorithme EM.
Nous pouvons grâce à cette loi a posteriori calculer l’espérance de la log-vraisemblance complète :
\[\begin{aligned} Q(\theta | \theta^{(k)}) &= \mathbb{E}_{\mu_0 | Y, \theta^{(k)}} [\log p(Y, \mu_0 | \theta)] \\ &= \sum\limits_{i=1}^T \log \ \mathcal{N}(y_i; \hat{\mu}^{(k)}, K_{\theta_i} + \sigma_i^2 I) + tr \left( (K_{\theta_i} + \sigma_i^2 I)^{-1} \hat{\Sigma}^{(k)} \right) \\ \end{aligned}\]L’étape M consiste à maximiser cette espérance par rapport aux paramètres \(\theta\) pour obtenir les nouveaux paramètres \(\theta^{(k+1)}\).
Définition d’un kernel Squared Exponential
- Définir une fonction
kern_se()qui calcule la matrice de covariance associée au kernel Squared Exponential (RBF) entre tous les couples de points \(x\) et \(x'\), contenus dans un vecteurX, tel que :
\[ k_{SE}(x, x') = v^2 \exp \left( -\frac{(x - x')^2}{2 l^2} \right) \]
- Calculer la matrice \(K_0\) du processus moyen latent sur une grille d’observation \(x\) de taille \(n = 10\), avec des hyperparamètres \(l_0 = 1\) et \(v_0 = 1\). Afficher cette matrice sous forme d’un tableau, puis sous forme d’image (utiliser la fonction
image()de R).
# Insert your code herePour la suite, on définit des hyperparamètres, par exemple pour \(T = 3\) tâches, au format suivant :
T = 3
theta = list(
list(l = 0.5, v = 1, sigma2 = 0.1),
list(l = 1, v = 0.5, sigma2 = 0.2),
list(l = 1.5, v = 1.5, sigma2 = 0.3)
)Implémentation de l’algorithme EM (étape E)
Implémenter une fonction e_step() qui calcule la moyenne et la covariance de la loi a posteriori de \(\mu_0\) conditionnellement aux observations \(Y\) et aux paramètres courants \(\theta\). La fonction doit prendre en entrée les observations Y, les paramètres courants theta, la grille d’observation x, ainsi que les hyperparamètres du processus moyen latent m0, K_0. Elle doit retourner une liste contenant la moyenne mu_hat et la covariance Sigma_hat de la loi a posteriori.
e_step <- function(Y, theta, x, m0, K0){
# Insert your code here
return(list(mu_hat = mu_hat, Sigma_hat = Sigma_hat))Implémentation de l’algorithme EM (étape M)
Implémenter une fonction m_step() qui maximise l’espérance de la log-vraisemblance complète \(Q(\theta | \theta^{(k)})\) par rapport aux paramètres \(\theta\). La fonction doit prendre en entrée les observations Y, la moyenne mu_hat et la covariance Sigma_hat calculées lors de l’étape E, ainsi que la grille d’observation x. On pourra par exemple utiliser la fonction optim() pour l’optimisation. Elle doit retourner les nouveaux paramètres theta_new.
m_step <- function(Y, mu_hat, Sigma_hat, x){
# Insert your code here
return(theta_new)
}Algorithme EM complet
Implémenter une fonction em_algorithm() qui exécute l’algorithme EM complet en alternant les étapes E et M jusqu’à un nombre maximal d’itérations. La fonction doit prendre en entrée les observations Y, la grille d’observation x, les hyperparamètres du processus moyen latent m0, K_0, les paramètres initiaux theta_init, le nombre maximal d’itérations max_iter. Elle doit retourner les paramètres estimés theta_est.
em_algorithm <- function(Y, x, m0, K0, theta_init, max_iter = 100){
# Insert your code here
return(theta_est)
}